
单击以查看Tosska DB Ace Enterprise (DBAP™) for PostgreSQL 1.0.5 发行说明
Tosska DB Ace Enterprise (DBAP™) for PostgreSQL® – 系统需求
你能用多少种方法优化带有”NOT IN”子询查在SQL PostgreSQL ?
在我的最新博客文章中,我将探讨针对使用 “NOT IN” 子查询的 SQL 语句的额外优化方案。
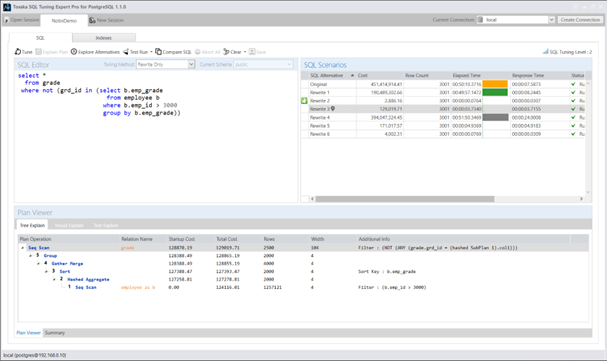
以下是一个带有 NOT IN 子查询的 SQL 示例。该语句从成绩表(grade)中查询记录,要求当员工表(employee)中 emp_id 大于 3000 时,grd_id 不匹配任何 emp_grade 值:
select *
from grade
where grd_id not in (select b.emp_grade
from employee b
where b.emp_id > 3000)
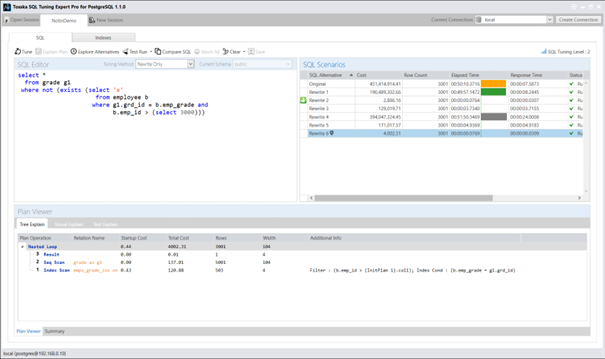
在我上一篇文章中,通过将原始查询改写为使用NOT EXISTS语句,在我的数据库环境中实现了最佳性能表现。然而需要注意的是,这种方法并非对所有数据库结构设计都普遍适用:
select *
from grade g1
where not (exists (select ‘x’
from employee b
where g1.grd_id = b.emp_grade and
b.emp_id > 3000))
现在我将列出其他高性能解决方案:
方案1——添加GROUP BY子句
通过添加GROUP BY子句,可促使优化器预先对员工表进行排序和哈希聚合处理:
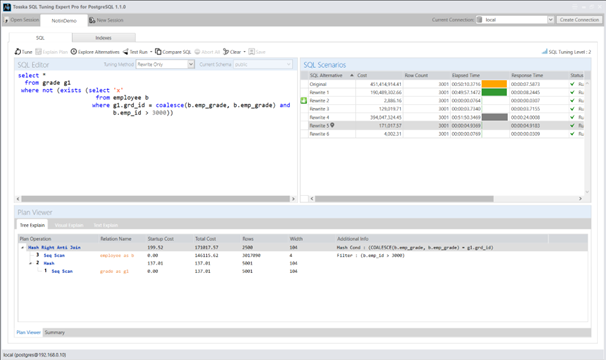
方案2——添加COALESCE函数
通过添加COALESCE(b.emp_grade, b.emp_grade),会阻止员工表(employee)使用潜在索引,导致该表被迫进行顺序扫描(Seq Scan),从而改变原查询执行路径中的连接顺序:
方案3——替换字面值为子查询
通过将字面值3000替换为子查询(SELECT (3000)),会隐藏常量特性,从而阻止优化器在b.emp_id字段上使用索引:
Tosska SQL Tuning Expert Pro for PostgreSQL – Tosska Technologies Limited
如何优化 PostgreSQL 中带 “NOT IN 子查询” 的 SQL 语句 ?
以下是一个使用 NOT IN 子查询的 SQL 语句示例。该查询从 Grade 表中检索记录,条件是当 emp_id 大于 3,000 时,grd_id 不与 employee 表中的任何 grd_id 匹配:
select *
from grade
where grd_id not in (select b.emp_grade
from employee b
where b.emp_id > 3000)
当前执行计划耗时异常漫长,需要 50 分 10 秒 才能完成。

该查询计划显示,系统先在Employee表上对Emp_id > 3000进行顺序扫描,生成物化临时存储,随后用Grade表的Grd_id进行过滤。这种查询计划效率极低——因为当Grade表的5000行记录需要逐行处理时,需反复扫描Employee表约300万条记录。
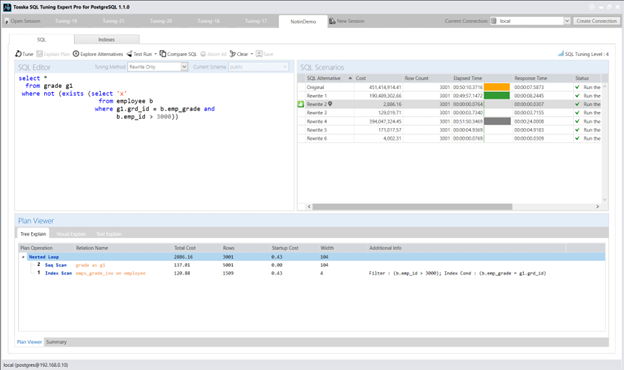
为解决此问题,我将SQL语句重写为NOT (EXISTS …)形式:
select *
from grade g1
where not (exists (select ‘x’
from employee b
where g1.grd_id = b.emp_grade and
b.emp_id > 3000))
优化后的查询计划显示:现在通过嵌套循环连接(Nest Loop),以Grade表为驱动,配合Employee表上的索引扫描(emps_grade_inx) 进行操作。
重写后的SQL语句执行时间降至0.07秒,性能得到显著提升。

重写后的SQL比原始版本提速超过43,000倍。这类优化同样可通过Tosska SQL Tuning Expert Pro for PostgreSQL工具实现。下图展示了几种性能更优的SQL替代方案,但因篇幅所限不便在本文详述,也许我们可以稍后再讨论这个话题。
Tosska SQL Tuning Expert Pro for PostgreSQL – Tosska Technologies Limited
在 PostgreSQL 中优化含 ‘IN’ 子查询的 SQL 语句有哪些方法 ?
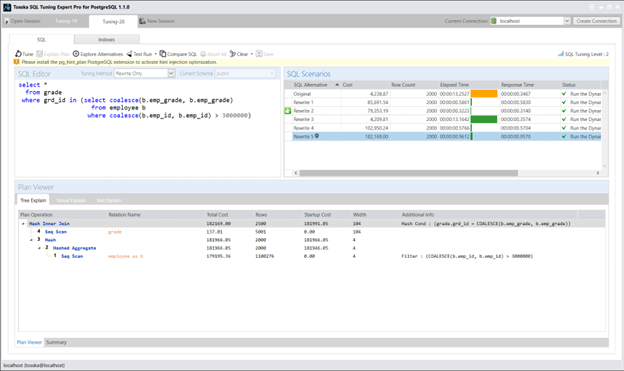
以下是我近期博客中的一条 SQL 语句。有读者询问在子查询的选择列表添加 +0(例如 b.emp_grade+0)对性能的影响。我很欣喜地得知,这个 +0 解决方案大约在 20 年前首次由我提出,用于解决特定子查询问题。不过该方法现已被 COALESCE(b.emp_grade, b.emp_grade) 替代——此举既能规避数据类型检测,又可预防意外错误。
今天,我想进一步探讨利用 IN 子查询优化 SQL 的其他解决方案。
select *
from grade
where grd_id in (select b.emp_grade
from employee b
where b.emp_id > 3000000)

以下截图展示了由 Tosska SQL Tuning Expert Pro 通过’仅重写’选项和 ‘SQL调优智能=2’ 生成的替代SQL方案。我将分享更多SQL重写方法,全面展示各种可能方案,期待以SQL调优技术的精妙艺术激发读者的探索热情。
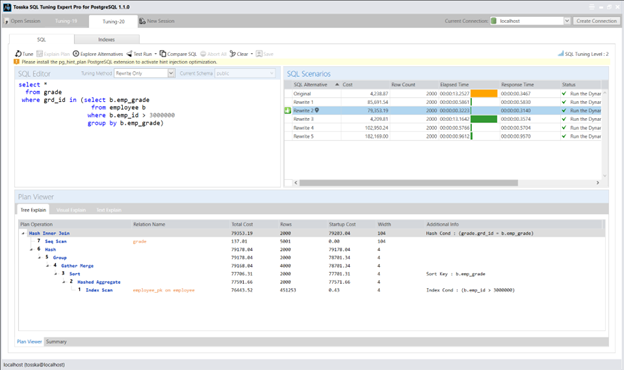
以下虽不深入探讨具体SQL重写语句细节,但我很乐意分享其余查询重写方案及其对应的执行计划:
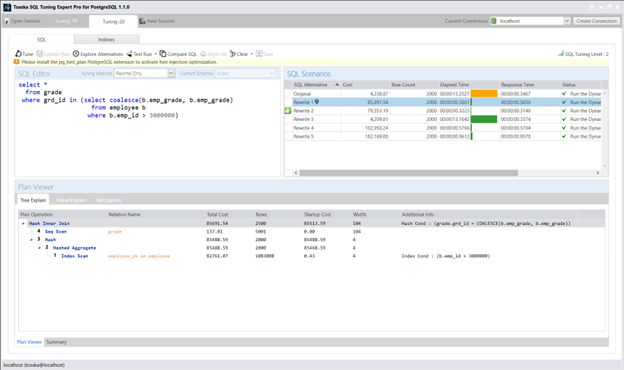
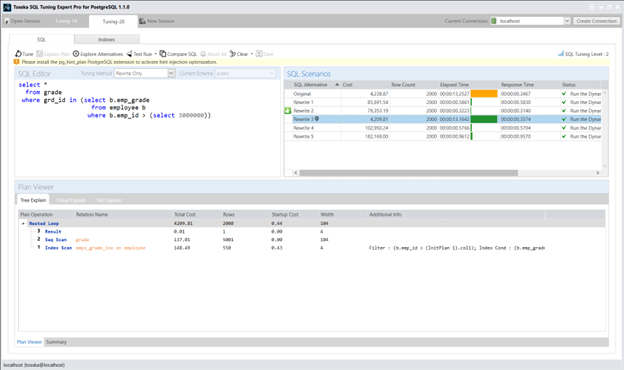
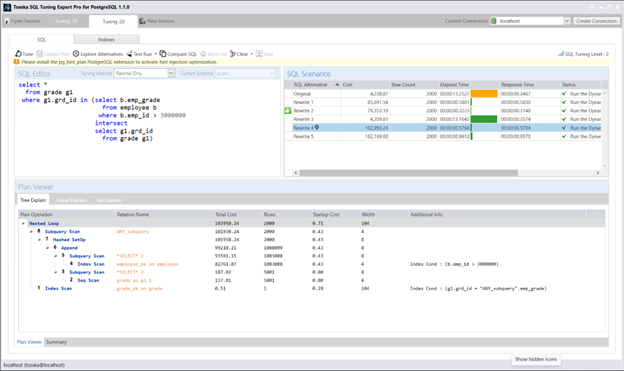
Tosska SQL Tuning Expert Pro for PostgreSQL – Tosska Technologies Limited
如何对 PostgreSQL 中的“IN 子查询”进行 SQL 调优 ?
以下是一个使用 IN 子查询的 SQL 语句示例。该查询从 grade 表中检索所有 grd_id 匹配 employee 表中 emp_id 大于 3,000,000 的记录的 emp_grade 的数据:
select *
from grade
where grd_id in (select b.emp_grade
from employee b
where b.emp_id > 3000000)
查询的执行计划显示,该语句耗时 12.6 秒。

该查询计划显示,优化器采用了 嵌套循环(Nested Loop) 连接方式:先对 grade 表进行全表顺序扫描(Sequential Scan),再对 employee 表进行索引扫描(Index Scan)。然而,这种执行逻辑会导致 每个 grade 表的记录都会触发一次针对 employee 表中 emp_id > 3,000,000 条件的索引扫描。虽然 employee 表总记录约 400 万条,但满足 emp_id > 3,000,000 的记录不足 100 万条。
为解决此问题,我通过在子查询中增加 GROUP BY 子句重写了 SQL:
select *
from grade
where grd_id in (select b.emp_grade
from employee b
where b.emp_id > 3000000
group by b.emp_grade)
修改后的查询计划发生以下关键变化:
- GROUP BY 子句强制子查询优先执行.
- 通过索引扫描快速筛选出 employee 表中 emp_id > 3,000,000 的记录.
- 对 emp_grade 列进行分组操作,消除重复值。
- 将 grade 表与已分组的 emp_grade 子集通过哈希表高效关联。
优化后的 SQL 执行时间降至 0.54 秒,性能显著提升。

优化后的 SQL 语句比原始版本 性能提升超过 23 倍。此类优化也可以通过 Tosska SQL Tuning Expert Pro for PostgreSQL 工具实现。在下方的截图中,虽然展示了其他性能更优的 SQL 改写方案,但受限于篇幅无法在此详述——我们后续可以进一步探讨这一主题。
Tosska SQL Tuning Expert Pro for PostgreSQL – Tosska Technologies Limited
如何对PostgreSQL中使用CASE表达式的SQL语句进行调优 ?
以下是一个包含CASE表达式语法的简单SQL语句:
SELECT *
FROM employee
WHERE
CASE
WHEN emp_salary< 1000
THEN ‘low’
WHEN emp_salary>100000
THEN ‘high’
END = :a
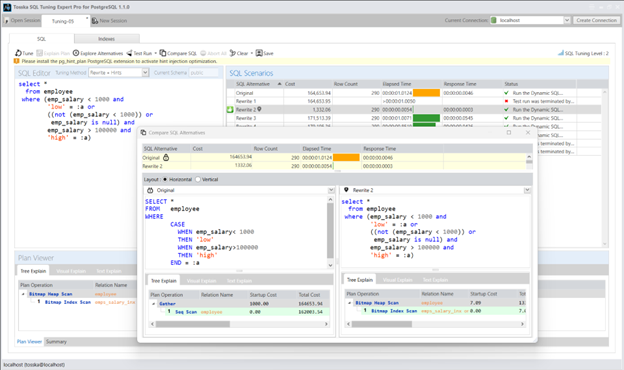
以下是该SQL语句的查询计划(当绑定变量:a等于’low’时,执行时间为1.01秒)。由于CASE表达式无法利用emp_salary索引,查询需要对EMPLOYEE表进行全表扫描。
我们可以通过使用多个OR条件将CASE表达式重构为以下语法:
select *
from employee
where (emp_salary < 1000 and
‘low’ = :a or
((not (emp_salary < 1000)) or
emp_salary is null) and
emp_salary > 100000 and
‘high’ = :a)
通过将多个OR条件与AND操作(例如’low’ = :a)结合,可以有效禁用对EMPLOYEE表的不必要数据搜索。
以下是重构后SQL的查询计划(执行速度提升至0.005秒),性能比原始语法快约200倍。新的查询计划显示使用了emp_salary索引的位图索引扫描(Bitmap Index Scan)。
这类SQL重写可以通过Tosska SQL Tuning Expert for PostgreSQL自动完成。实际上,还存在其他性能更优的改写方法,但由于篇幅限制无法在此详述,后续可能会在我的博客中进一步探讨。
Tosska SQL Tuning Expert Pro for PostgreSQL – Tosska Technologies Limited