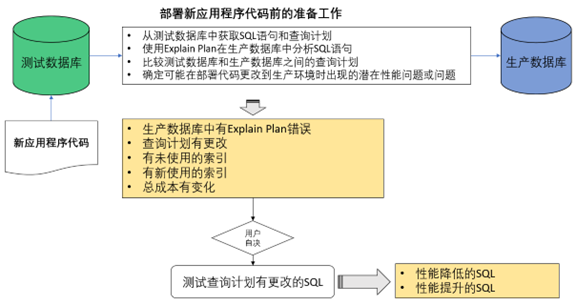
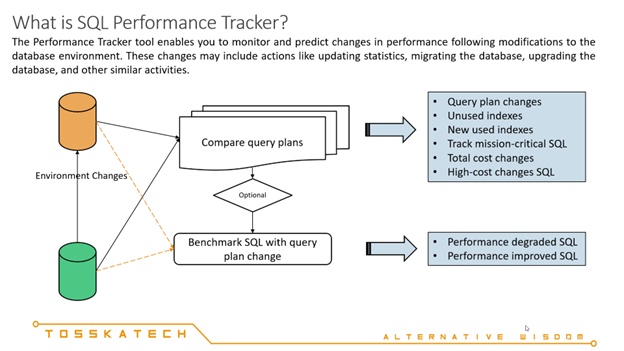
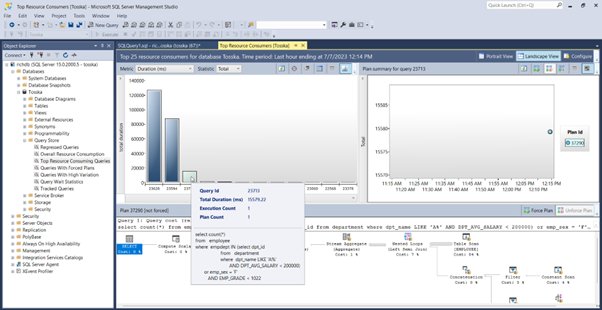
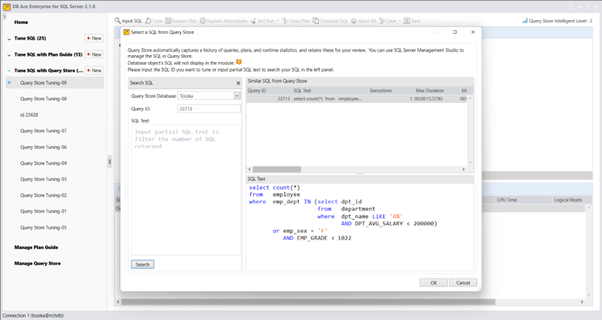
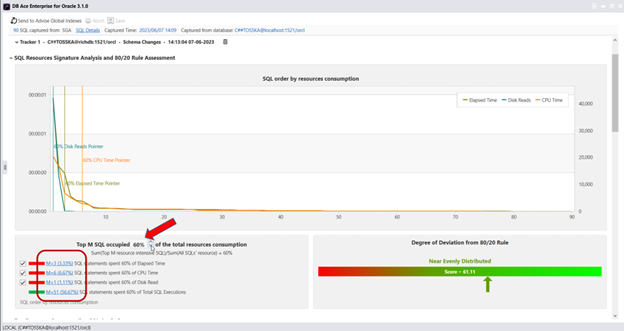
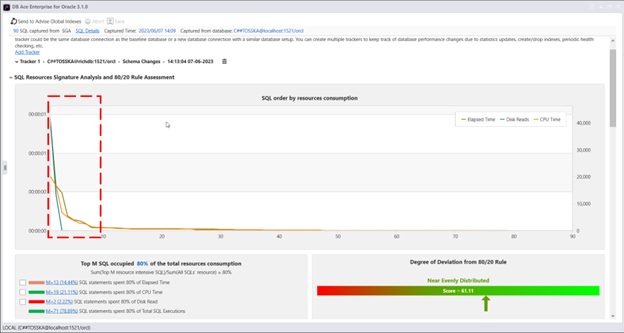
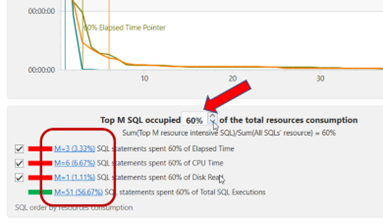
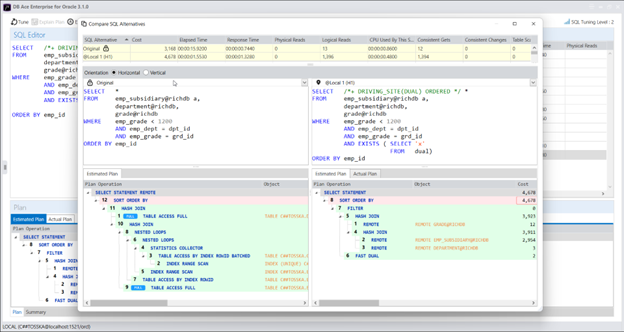
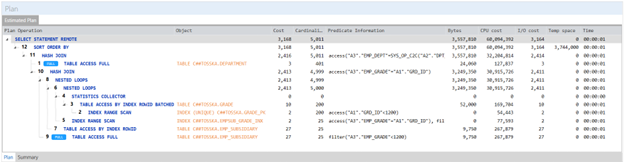
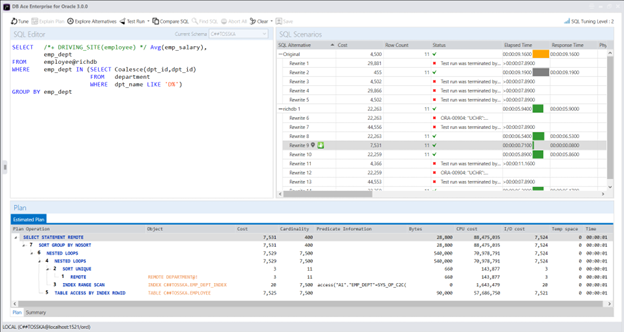
在 MS SQL Server 中使用计划指南来调优第三方应用程序的 SQL 可以是一种有用的技术,当您需要优化应用程序生成的特定查询或查询集的性能,而无需更改应用程序源代码时。
以下是在 MS SQL Server 中使用计划指南来调优第三方应用程序的 SQL 的步骤,而无需更改源代码:
- 鉴定导致应用程序性能问题的查询或查询集。您可以使用 SQL Server Profiler 或扩展事件来捕获和分析应用程序生成的 SQL 语句。
- 创建计划指南,为已鉴定的查询或查询集提供优化的执行计划。这可以涉及修改查询文本或提供查询提示以影响优化器的决策。
- 测试计划指南,确保它提供了期望的性能改进,并且不会引起任何意外的副作用。
- 将计划指南部署到生产环境,并监控应用程序的性能,确保计划指南被使用,并且提供了期望的性能改进。
在优化应用程序源代码中的临时 SQL 语句之前,了解 SQL 语句如何与计划指南中指定的语句匹配是至关重要的,包括空格和注释。此外,还需要匹配 SQL 语句的来源。
以下是用于创建计划指南的系统存储过程:

今天的重点将放在使用计划指南来调优临时 SQL (@type = N’SQL’) 上。SQL 有两种类型:独立的 SQL (@module_or_batch = NULL) 和批处理文本中的 SQL (@module_or_batch = N’batch_text’)。例如,如果一个应用程序发送了以下 SQL,并且它独立执行而没有其他代码,那么它属于独立的 SQL。
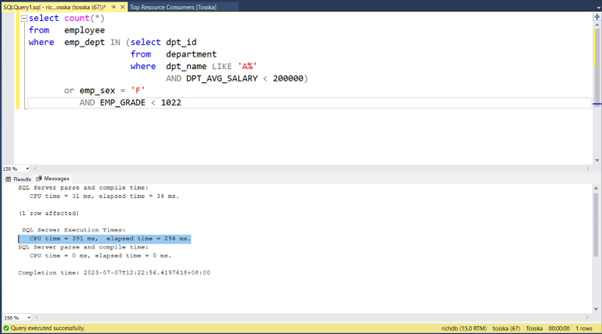
select top 10 * from employee;
下面的示例展示了一个批处理文本,其中包含了上述列出的 SQL 语句之一,需要通过计划指南进行优化。这个 SQL 语句位于批处理文本的中间。由于相同的 SQL 语句可能来自批处理文本,我们必须通过使用变量 @module_or_batch = N’batch_text’ 来指定具体的批处理文本。因此,必须为同一个 SQL 语句创建两个计划指南,一个用于临时 SQL,一个用于批处理文本。为了准确地确定临时 SQL 的来源,建议使用 SQL Profiler 来捕获需要通过计划指南进行优化的 SQL 语句。
select count(*) from employee;
select top 10 * from employee;
where emp_id in (select emp_id id
from emp_subsidiary
where emp_dept<‘h’)
order by emp_name;
Microsoft SQL Server Management Studio提供了一个有用的工具,可以帮助用户创建计划指南,而无需手动执行系统存储过程。然而,了解被优化的SQL语句的类型以及需要输入的相应参数的含义是至关重要的。
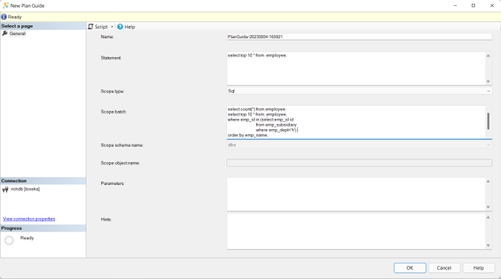
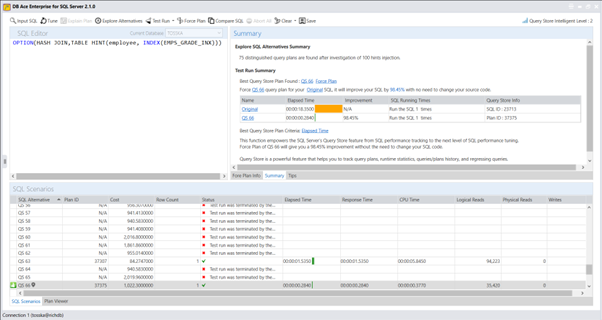
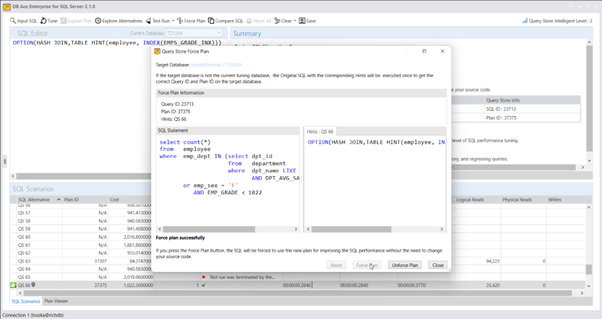
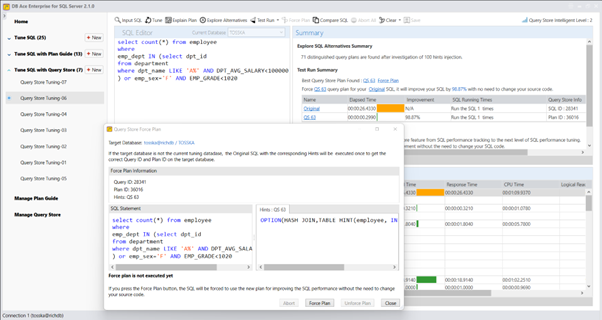
尽管对于初学者来说,创建计划指南的步骤可能看起来很复杂,但它们对于在不修改源代码或没有修改权限的情况下改善SQL性能是值得的。然而,最具挑战性和耗时的方面是找到SQL语句的最佳查询提示(@hints = N’OPTION(query_hint [ ,…n ]))。除非您对SQL调优技术有深入的了解并且有足够的时间进行实验,否则您可能需要一个能够从捕获SQL、识别SQL来源类型、自动调优查询提示并便于部署计划指南的产品来简化这个过程。
Tosska DB Ace Enterprise for SQL Server – Tosska Technologies Limited
DBAS Tune SQL PG Standalone – YouTube
DBAS Tune SQL PG Batch – YouTube