MySQL中的Query Rewriter插件是一个组件,允许您在执行SQL之前修改传入的SQL查询。它提供了根据特定需求转换、路由、过滤或扩展查询的能力。该插件在SQL层操作,并可用于优化查询性能、强制执行安全策略、实施数据分区策略或向查询添加附加业务逻辑。通过Query Rewriter插件,您可以自定义和塑造SQL查询,以满足特定需求,在MySQL服务器内灵活控制查询执行。
Query Rewriter查询转换功能使您能够将原始查询重写或转换为等效或更高效的形式。这对于优化性能、简化复杂查询或强制使用特定查询计划非常有用。
在使用此功能之前,您必须安装Query Rewriter插件。Query Rewriter的概念很简单,它是一组预定义的SQL语句,用于替换从应用程序程序触发的特定SQL语句模式。
如果您已安装了该插件,以下SQL语句可用于定义您的SQL替换规则和错误消息处理。
INSERT INTO query_rewrite.rewrite_rules (message, pattern, replacement)
VALUES(Unique_ID, Original_SQL, Rewrite_SQL);
在MySQL中,query_rewrite.rewrite_rules表存储了Query Rewriter插件用于重写SQL查询的规则。该表具有两列:
Pattern – 此列表示触发SQL查询重写的模式或条件。它定义了要匹配的特定查询或查询模式。
Replacement – 此列指定应应用于匹配的查询或查询模式的替换或转换。
当执行SQL查询时,Query Rewriter插件会检查query_rewrite.rewrite_rules表以查找匹配的模式。如果某个模式与执行的查询匹配,插件将使用相应的替换来重写查询。这使您能够根据特定的模式或条件修改查询结构、优化查询或添加自定义逻辑。
我利用message列来定义SQL替换规则的临时唯一标识,这样可以使用以下SQL提取实际的规则ID。
SELECT id into :SID FROM query_rewrite.rewrite_rules where message= Unique_ID;
当您对query_rewrite.rewrite_rules表中的查询重写规则进行更改时,这些更改不会立即生效。相反,MySQL会将规则缓存在内存中以提高性能。然而,如果您希望确保更新后的规则立即生效,可以调用query_rewrite.flush_rewrite_rules()函数。
CALL query_rewrite.flush_rewrite_rules();
如果发生加载错误,插件还会将Rewriter_reload_error状态变量设置为ON,并将错误消息存储在Message列中。
SELECT message FROM query_rewrite.rewrite_rules where id=:SID;
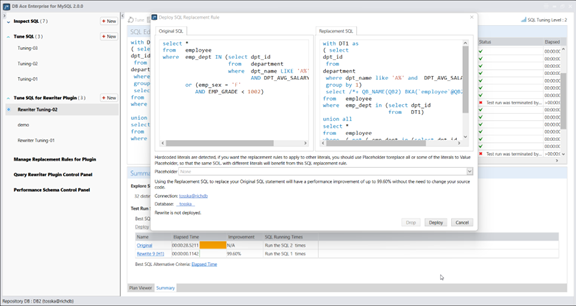
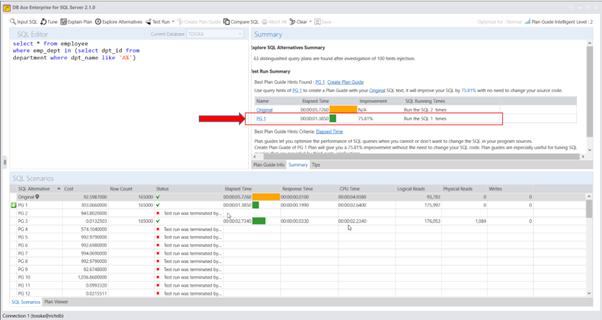
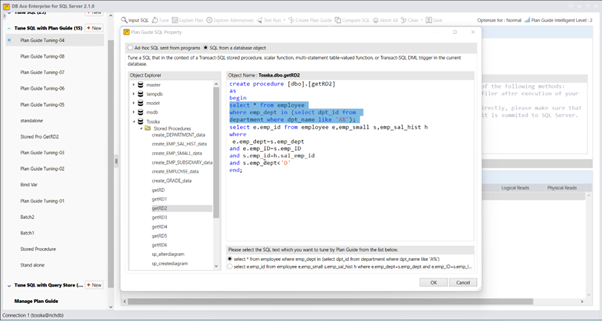
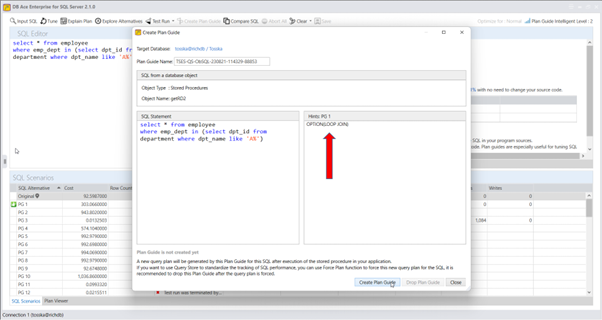
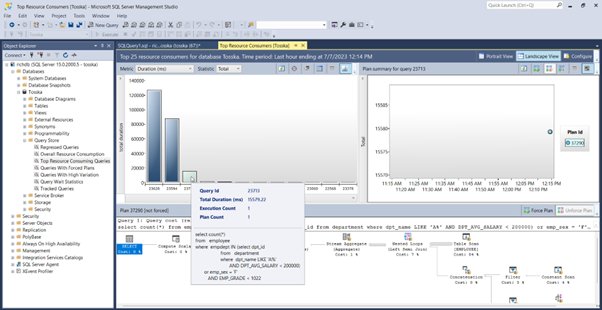
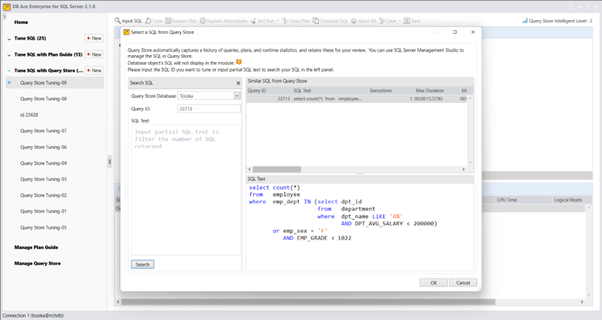
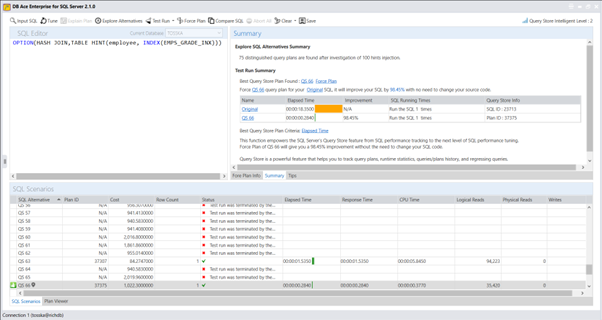
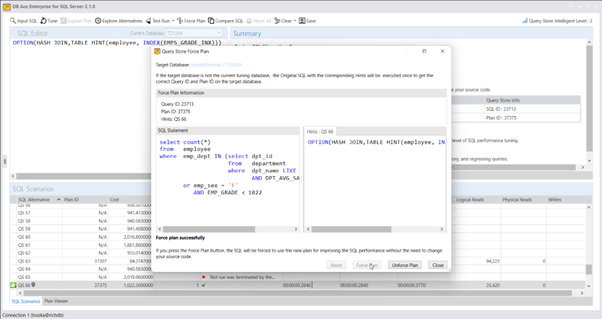
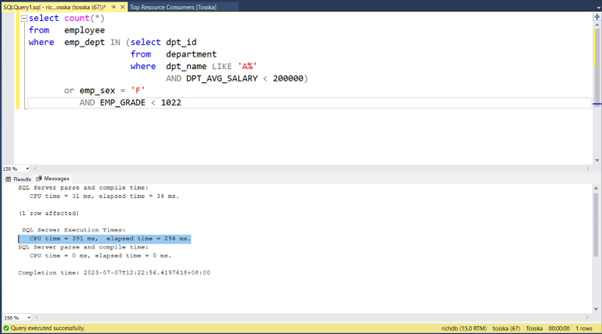
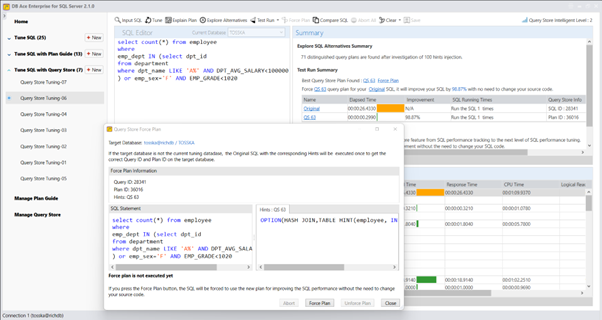
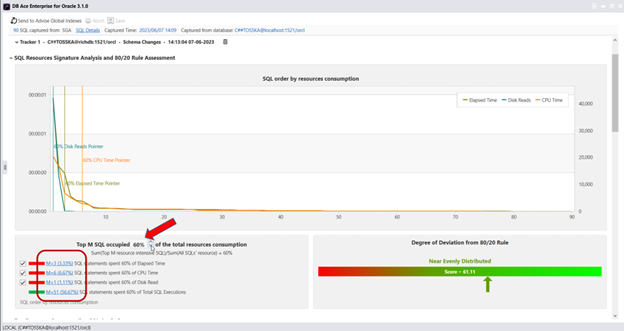
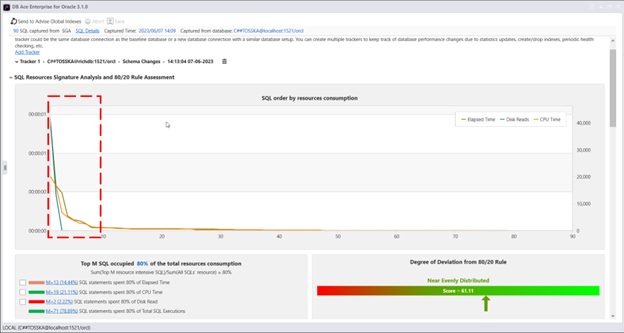
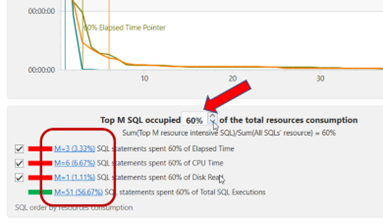
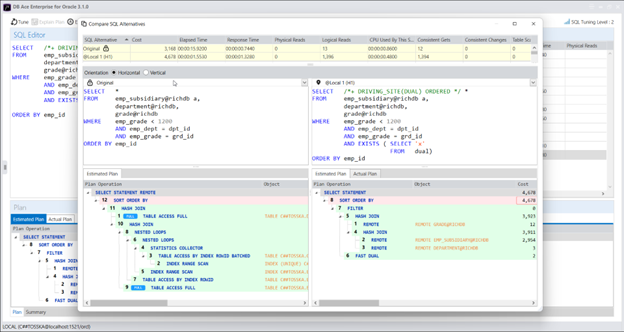
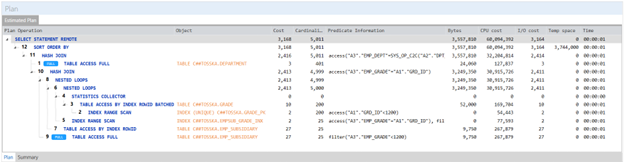
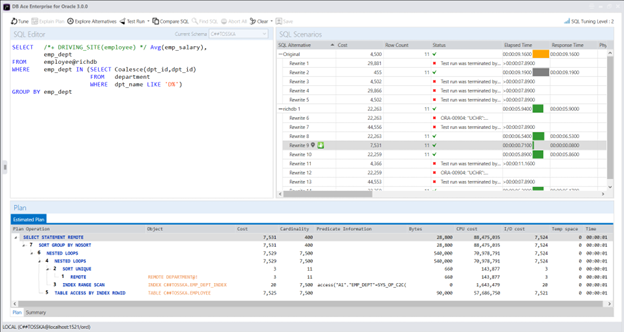
实际上,Query Rewriter插件功能强大且易于使用。最具挑战性的方面是为性能不佳的SQL语句找到替代的SQL语句。Tosska DB Ace Enterprise for MySQL可以帮助您自动化这个过程,从识别性能不佳的SQL语句到重写SQL语法和部署替代规则。
Tosska DB Ace Enterprise for MySQL – Tosska Technologies Limited
DBAM Tune Rewriter demo – YouTube