在我上一篇文章中,带有Exists子查询的SQL语句通过以下改写执行速度快了90倍。
SELECT *
FROM DEPARTMENT
where exists (select ‘x’
from employee
where emp_id > 2700000
and emp_dept=DPT_ID)
执行计划:
改写的SQL语句:
select *
from DEPARTMENT
where DPT_ID in (select isnull(emp_dept,emp_dept)
from employee
where emp_id > 2700000)
group by emp_dept)
执行计划:
语法改写的解决方案
DBA或者开发人员通常使用语法改写技术来改进SQL语句,尤其是对于Oracle或者MySQL数据库,但对于MS SQL Server或者IBM Db2 LUW的用户来说语法改写并不容易使用。原因是MS SQL Server和IBM Db2 LUW在它们的SQL优化器中有一个强大的内部改写引擎。这个内部SQL改写引擎会尝试将SQL语法改写为它们的内部规范语法。这意味着,无论您如何改写您的SQL语句,MS SQL Server或者IBM Db2 LUW都会尝试将SQL重新改写回它们内部假定的最优语法。所以如果假定的最优语法不好,就很难调优SQL。因为用户不容易通过简单的SQL改写来影响数据库SQL优化器生成更好的执行计划。
查询提示解决方案
为了解决这个问题,SQL Server为用户提供了查询提示功能,以帮助它的SQL优化器生成更好的执行计划。 它不像SQL改写方法,经验丰富的开发人员可能会说出改写SQL的最终执行计划是什么。查询提示是一个精确的解决方案,它通常应用于整个执行计划中的特定步骤,但对特定步骤的更改将会对整个执行计划的其他步骤产生多米诺效应。因此MS SQL Server必须调整其它步骤以实现用户对SQL语句中查询提示的预期。所以最终的执行计划并不容易被用户预测,尤其是对复杂的SQL语句。
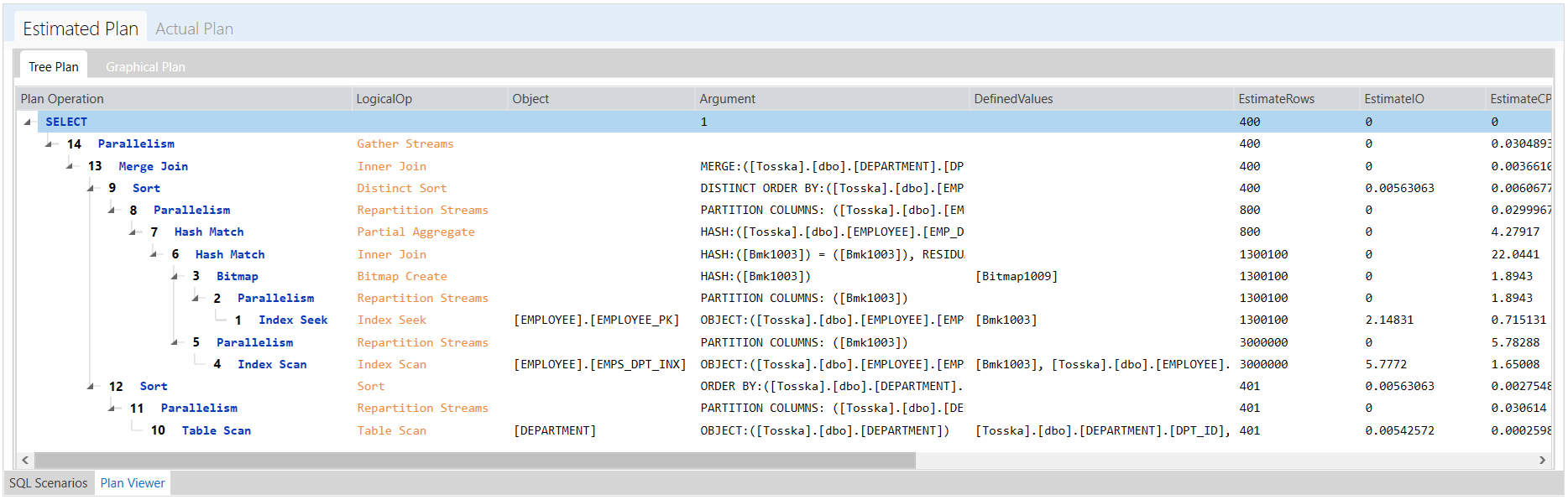
以下由Tosska SQL Tuning Expert生成带提示的SQL比原来的SQL快了4倍左右,耗时0.639秒。
select *
from DEPARTMENT
where exists (select ‘x’
from employee
where emp_id > 2700000
and emp_dept = DPT_ID) OPTION(LOOP JOIN,HASH GROUP)
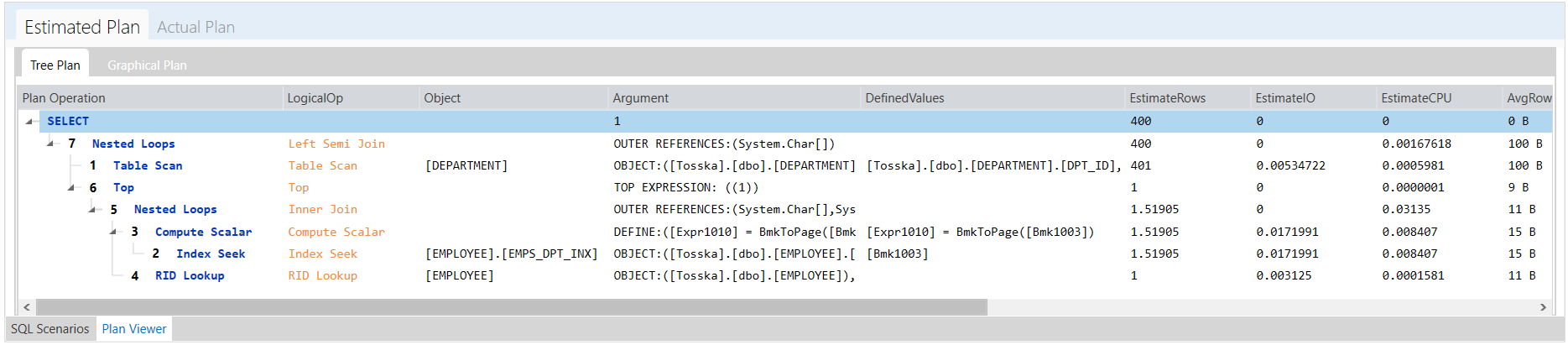
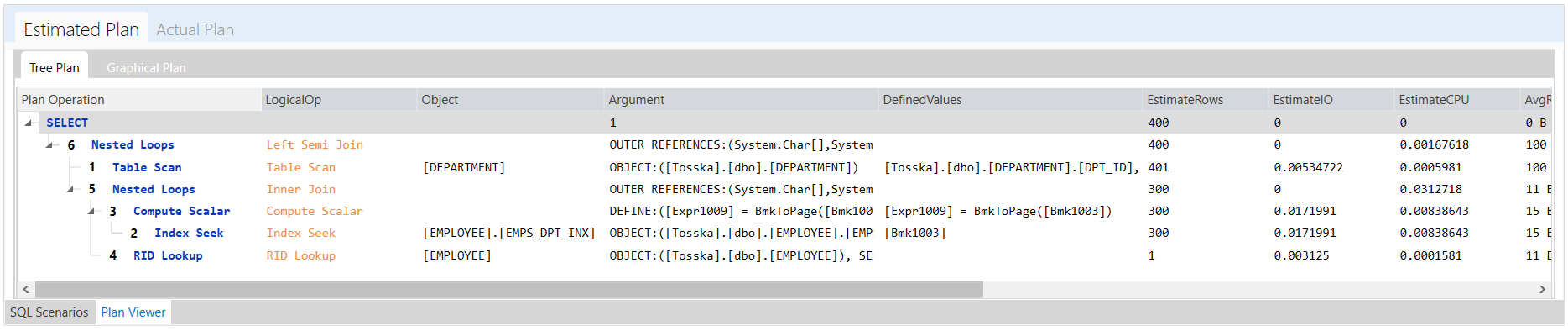
还有一个带提示的SQL,它比原始的SQL快了50倍左右,只需0.055秒。这个执行计划非常接近我上一篇文章中的改写调优。
select *
from DEPARTMENT
where exists (select ‘x’
from employee WITH(INDEX(EMPS_DPT_INX))
where emp_id > 2700000
and emp_dept = DPT_ID)
语法改写加提示的解决方案
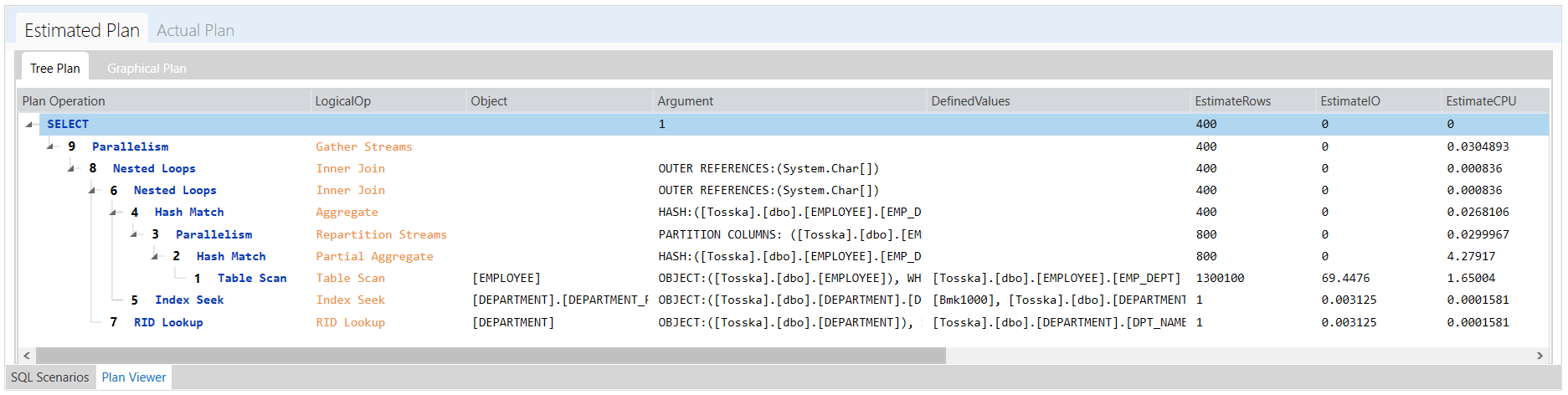
对于一些SQL语句,语法改写或者提示方法可能无法单独解决一个复杂的SQL性能问题,有些人可能会想,是否有可能同时改写和应用提示来改进一条SQL语句?是的,这在Tosska SQL Tuning Expert人工智能引擎中是可能的,这种技术可以解决更多的SQL性能问题。稍后我将在我的博客中讨论这项技术。
Tosska SQL Tuning Expert (TSES™) for SQL Server® – Tosska Technologies Limited
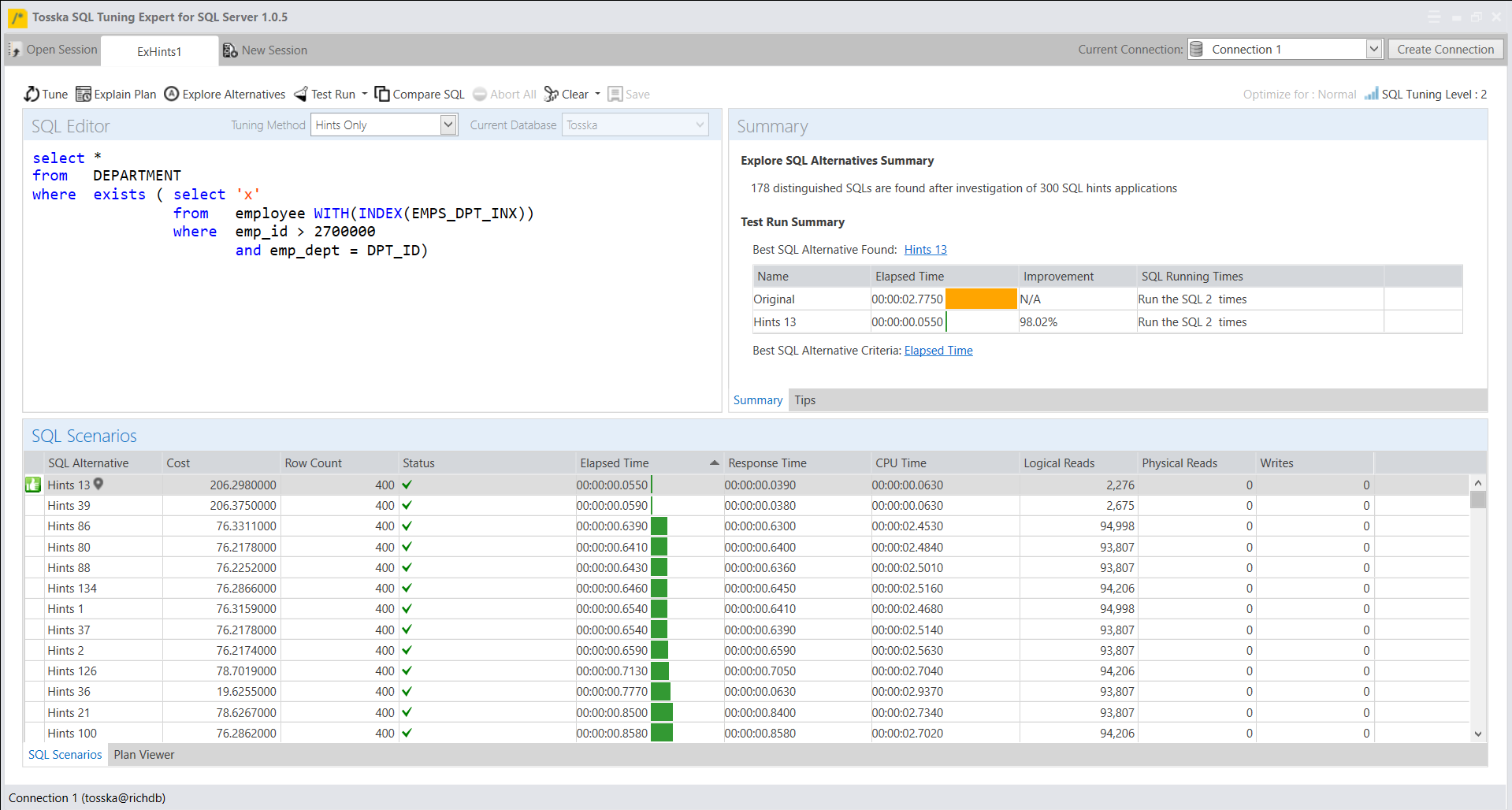
下面显示Tosska SQL Tuning Expert在考察300种加提示的SQL写法后挑选出178条等价SQL,这远远超出了一个专家在10分钟内所能达到的水平。MS SQL Server是市场上对提示注入最敏感的数据库,SQL Server的查询提示通常能够影响SQL优化器生成特定的执行计划,因此MS SQL Server的SQL调优远比其他数据库更具挑战性。