Tosska DB Ace Enterprise (DBAO™) for Oracle 3.2.0 发行说明


非常智慧
性能部署是软件部署中一个常常被忽略的地方。尽管确保软件正确部署很重要,但在生产环境中优化性能同样重要。通过在软件部署过程中认识到性能部署的重要性,开发人员可以确保其软件运行良好,并满足用户的需求。关注性能部署可以帮助防止性能问题并提高用户对软件的满意度。
测试数据库与生产数据库之间性能部署的缺失环节
尽管进行了广泛的预部署测试,但在软件性能部署过程中仍有可能在特定的开发环境中遇到性能问题。以下问题可能会出现 :
所以用户在发布新应用程序代码后遇到性能问题或应用程序错误并不罕见。
通过预先部署流程确保性能部署
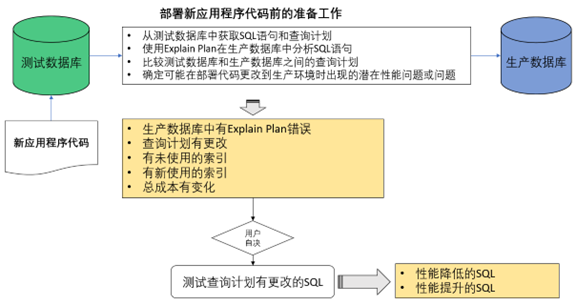
以下说明提供了一种保证软件性能可靠性的新方法。这个想法很简单:由于在生产数据库上运行新的应用程序代码是不可行的,为什么不为生产数据库中的每个SQL语句获取查询计划呢?这样,我们就可以评估每个应用程序代码中的SQL语句在生产数据库上的性能。
假设新应用程序代码中有10个SQL语句需要在测试数据库中识别。在这种情况下,我们需要先清除共享池并在测试数据库中执行新的应用程序,以隔离这10个语句。这个过程将使我们能够捕获和分析这10个SQL语句,并从生产数据库中获取它们的查询计划。下面的表格呈现了查询计划比较所导致的各种潜在结果。
| 观察结果 | 可能的原因 |
| 生产数据库中有Explain Plan错误 | SQL语句需要访问生产数据库中不存在的对象 |
| 查询计划有更改 | 测试和生产数据库之间存在显著的统计差异,包括数据库模式的差异。这些模式差异可能涉及缺少或新的分区以及其他影响数据库结构和组织的变化。由于潜在的重大性能变化,可能需要对SQL进行基准测试。 |
| 有未使用的索引 | 一些在测试数据库中使用的索引在生产数据库中未使用, 由于潜在的重大性能变化,可能需要对SQL进行基准测试。 |
| 有新使用的索引 | 一些在生产数据库中使用的索引在测试数据库中未使用, 由于潜在的重大性能变化,可能需要对SQL进行基准测试。 |
| 总成本有变化 | 10个SQL语句的整体查询计划成本发生变化。如果生产数据库的数据量大于测试数据库,则成本变化将更高。 |
DBAO SQL Performance Tracker – YouTube
Tosska DB Ace Enterprise for Oracle – Tosska Technologies Limited
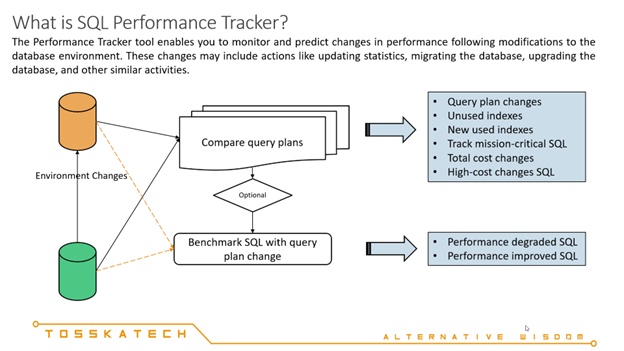
要正确评估数据库环境变化期间一组SQL语句的性能影响,必须深入了解SQL查询性能可能受到的影响。SQL查询可能发生的两种主要性能变化类型。我称之为“渐进性变化”的第一种类型通常是由统计数据的变化引起的,例如相关表或索引页面中数据量的波动。如果统计数据的变化不足以触发新的查询计划,查询计划将保持不变,并且与原始统计数据相比,SQL查询的性能不会有很大的变化。
第二种性能变化类型称为“跳跃性变化”,是由于统计数据或模式发生重大变化而引入新的查询计划。这种类型的变化可能对性能产生重大影响,有时会导致性能灾难。
在更改数据库环境时,必须密切监视SQL查询的性能,并采取适当措施来优化受影响的语句。为了跟踪环境变化前后的关键SQL语句,可以遵循以下一般步骤:
如果您只需要跟踪少量SQL语句的性能在环境变化前后的变化,上述步骤可以手动完成。但是,如果您需要监视数百个SQL语句而没有工具,则可能会很具有挑战性。 Tosska DB Ace for Oracle配备了一个强大的工具,可以帮助您跟踪两个数据库之间SQL语句的性能差异。
DBAO SQL Performance Tracker – YouTube
Tosska DB Ace Enterprise for Oracle – Tosska Technologies Limited
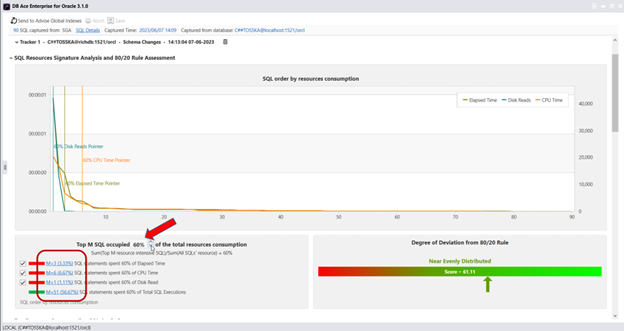
之前的文章“如何使用80/20法则来调优数据库应用程序 I”演示了如何应用80/20法则来评估数据库中SQL工作负载的整体性能。在本例中,展示了从Oracle SGA检索到的一组90个SQL语句的图表,每个语句按照其资源使用情况以降序排列列出,最具资源密集型的SQL在左侧。分析显示,大约14.44%的SQL语句占用了80%的总经过时间,而21.11%的SQL语句占用了80%的总CPU时间,表明SQL工作负载分布符合80/20法则。因此,调整SQL可能并不必要,因为这不太可能带来显著的性能改进。
然而,为了更加成本有效地进一步优化数据库性能,建议对高工作量SQL语句的前20%进行深入调查。这将揭示资源利用在前几个SQL语句中急剧下降,使它们成为优化的最关键候选项。
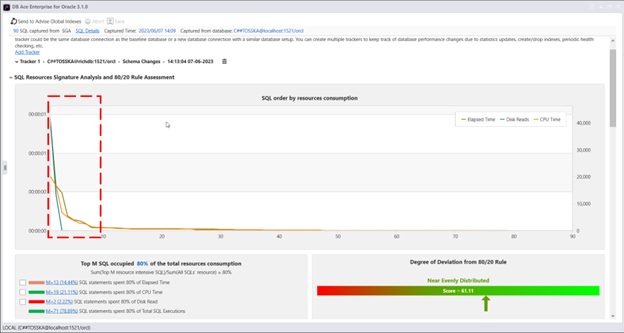
让我们将目标的总资源消耗比例从80%降低到60%,并检查负责利用这些资源的SQL语句。结果很有趣,显示出3个SQL语句占用了60%的经过时间,6个SQL语句占用了60%的CPU时间,而仅有一个SQL语句占用了60%的磁盘读取。通过专注于这些SQL语句,可以提高数据库工作负载高达60%。例如,如果数据库遇到IO瓶颈,专注于一个SQL语句可以节省高达60%的磁盘读取。
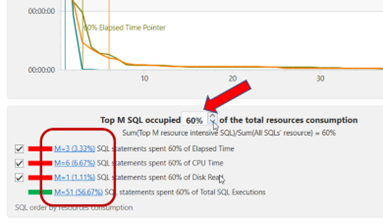
您可以利用Excel来进行上述80/20法则分析的模拟,提供SQL工作负载分布的全面概述。这种方法有助于快速评估数据库SQL性能的整体状况,以及优化高负载SQL语句的成本和效益。更进一步的SQL资源频谱分析已集成到我们的Tosska DB Ace for Oracle软件中。
Tosska DB Ace Enterprise for Oracle – Tosska Technologies Limited
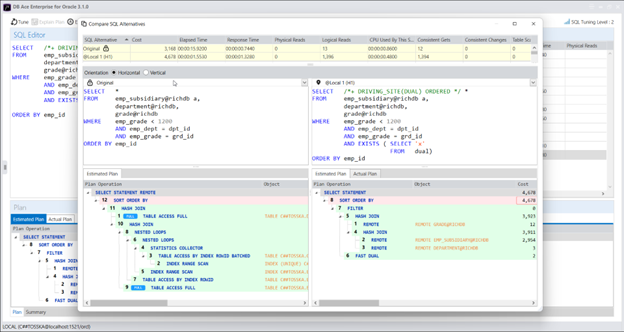
以下是一个 SQL 示例,查询从远程数据库 @richdb 检索员工、部门和等级表。
SELECT *
FROM emp_subsidiary@richdb a,
department@richdb,
grade@richdb
WHERE emp_grade < 1200
AND emp_dept = dpt_id
AND emp_grade = grd_id
ORDER BY emp_id
下面是此 SQL 的查询计划,它花费了 15.92 秒才能完成。查询计划的第一步是“SELECT STATEMENT REMOTE”,这意味着整个查询将在远程数据库 @richdb 上执行,并将结果发送回本地数据库。查询计划有点复杂,不容易判断是否最优。但如果查询在本地数据库 @local 上部分执行,我们可以尝试一件事情。
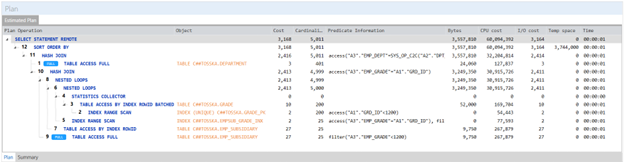
为了请求 Oracle 在本地数据库中执行某些连接操作,SQL 查询必须包含至少一个在本地数据库中执行的表。这才允许在 SQL 查询中使用提示 /*+ DRIVING_SITE ( [ @ queryblock ] tablespec ) */。如果没有表在本地数据库中显式执行,则没有办法请求 Oracle 尝试在本地数据库中执行连接操作。
我们可以在 SQL 中添加一个虚拟条件“EXISTS (SELECT ‘X’ FROM DUAL)”和提示 /*+ DRIVING_SITE(DUAL) */,以强制 Oracle 在本地数据库中执行一些连接操作。
SELECT /*+ DRIVING_SITE(DUAL) */ *
FROM emp_subsidiary@richdb a,
department@richdb,
grade@richdb
WHERE emp_grade < 1200
AND emp_dept = dpt_id
AND emp_grade = grd_id
AND EXISTS ( SELECT ‘x’
FROM dual)
ORDER BY emp_id
以下是修改后的 SQL 的查询计划,它花费了 4.08 秒,比原始 SQL 语句快约 4 倍,其中仅有一个连接操作在远程数据库中执行。

在 SQL 查询中添加 ORDERED 提示可以进一步优化查询。这将会将在上一个查询计划中标记的复合语句分解为单个表数据的远程提取,如下面的查询计划所示。
SELECT /*+ DRIVING_SITE(DUAL) ORDERED */ *
FROM emp_subsidiary@richdb a,
department@richdb,
grade@richdb
WHERE emp_grade < 1200
AND emp_dept = dpt_id
AND emp_grade = grd_id
AND EXISTS ( SELECT ‘x’
FROM dual)
ORDER BY emp_id

如果您熟悉 Oracle Exadata,您可能会注意到远程数据库 @richdb 中 REMOTE 表的数据检索过程,类似于 Exadata 存储服务器的工作方式。
需要记住的是,将此技术应用于具有 DB Link 的 SQL 查询只在某些环境下有益。例如,当网络速度良好、数据流量不大且本地数据库的工作负载较低时,这种技术是理想的。
Tosska DB Ace for Oracle 可以自动执行此类重写,从而生成一个比原始 SQL 查询快近 10 倍的 SQL 查询。
Tosska DB Ace Enterprise for Oracle – Tosska Technologies Limited
DBAO Tune DB Link SQL – YouTube
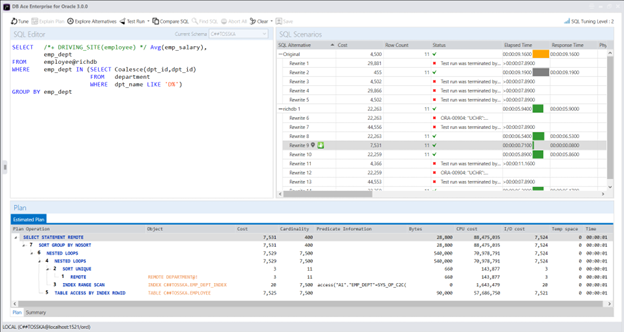
这里是一个示例SQL查询,用于计算本地数据库中以字母“D”开头的每个部门在远程数据库@richdb上员工的平均工资。
SELECT Avg(emp_salary),
emp_dept
FROM employee@richdb
WHERE emp_dept IN (SELECT dpt_id
FROM department
WHERE dpt_name LIKE ‘D%’)
GROUP BY emp_dept
以下是此SQL的查询计划,它需要9.16秒才能完成。查询计划显示从本地DEPARTMENT到远程EMPLOYEE数据库的嵌套循环。由于EMPLOYEE表的大小比DEPARTMENT表大得多,因此在这种情况下,嵌套循环连接路径不是最优的。

为了要求Oracle考虑在远程数据库@richdb中执行连接操作,我添加了一个提示/*+ DRIVING_SITE(employee) */,告诉Oracle使用EMPLOYEE表的数据库@richdb作为分布式查询的驱动站点。
SELECT /*+ DRIVING_SITE(employee) */ Avg(emp_salary),
emp_dept
FROM employee@richdb
WHERE emp_dept IN (SELECT dpt_id
FROM department
WHERE dpt_name LIKE ‘D%’)
GROUP BY emp_dept
以下查询显示驱动站点已更改为@richdb,并且远程从“本地”数据库检索DEPARTMENT数据。现在速度已经提高到5.94秒。但是查询计划有点复杂,有一个视图,由EMPLOYEE和DEPARTMENT的两个“索引快速完整扫描”的索引哈希连接构成。

我进一步更改了SQL,并在子查询的选择列表中添加了一个虚拟操作Coalesce(dpt_id,dpt_id),以阻止DEMPARTMENT表的索引快速全扫描。
SELECT /*+ DRIVING_SITE(employee) */ Avg(emp_salary),
emp_dept
FROM employee@richdb
WHERE emp_dept IN (SELECT Coalesce(dpt_id,dpt_id)
FROM department
WHERE dpt_name LIKE ‘D%’)
GROUP BY emp_dept
这个更改给SQL带来了一个新的查询计划,如下所示,性能显著提高至0.71秒。您可以从这个例子中了解虚拟操作Coalesce(dpt_id,dpt_id)如何影响Oracle SQL优化器的决策。

这种重写可以通过Tosska DB Ace for Oracle自动完成,它表明这个重写比原始SQL快了近13倍。
Tosska DB Ace Enterprise for Oracle – Tosska Technologies Limited
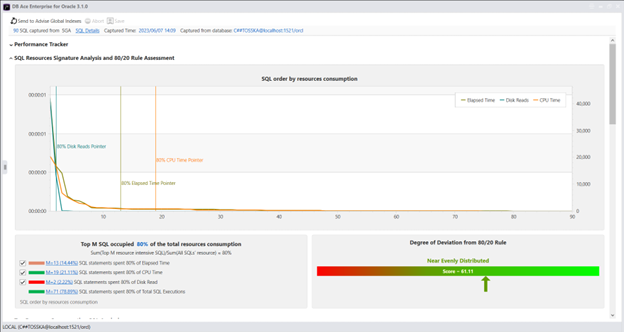
2002年,微软报告称,他们软件中大多数的错误和崩溃都是由他们检测到的少数bug引起的,具体来说大约是20%。这种现象,称为帕累托原理或八二法则,也适用于数据库SQL行为的分析。假定只有20%的SQL语句应该占据整个数据库系统80%的资源消耗。任何应用系统中,少于20%的SQL语句消耗了80%以上的数据库资源,都被认为是异常的,并应进行审查和优化。
使用SQL资源谱分析技术,用户可以设置资源阈值百分比(通常在80%左右)来确定负责大部分资源消耗的前M%的SQL语句。如果分析显示只有少数SQL语句(例如只有4%)负责超过总资源消耗的80%,则表明优化这些特定的SQL语句有可能显著提高整个数据库的性能。
以下的例子显示了从Oracle SGA获取的90个SQL语句集合,每个语句在图表中按其资源使用量列出,从左侧的最高消耗SQL开始以降序排列。分析显示,约14.44%的SQL语句占据了总经过时间的80%,而21.11%的SQL语句占据了总CPU时间的80%。这表明SQL工作负载的分布与80/20法则接近对齐。因此,可能没有急迫的需要进行SQL调优,因为这不太可能导致显着的性能提升。
另一个例子突显了SQL工作负载分布中对80/20法则的显著偏差。分析显示,大约有4个SQL语句占据了总经过时间的80%,而另外4个SQL语句则占据了总CPU时间的80%,还有2个SQL语句贡献了总磁盘读取量的80%。这表明,通过仅优化这4个SQL语句,可以在数据库的整体性能方面实现显著的改进。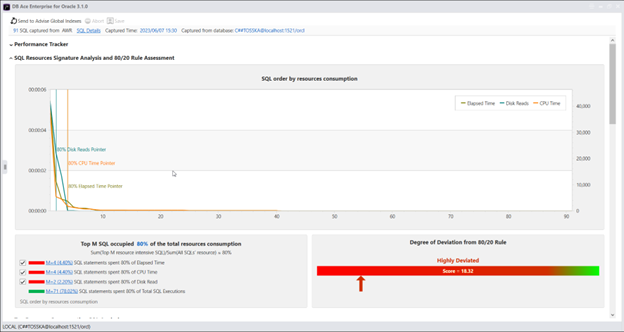
您可以利用Excel来进行上述80/20法则分析的模拟,提供SQL工作负载分布的全面概述。这种方法有助于快速评估数据库SQL性能的整体状况,以及优化高负载SQL语句的成本和效益。更进一步的SQL资源谱分析已集成到我们的Tosska DB Ace for Oracle软件中。
Tosska DB Ace Enterprise for Oracle – Tosska Technologies Limited