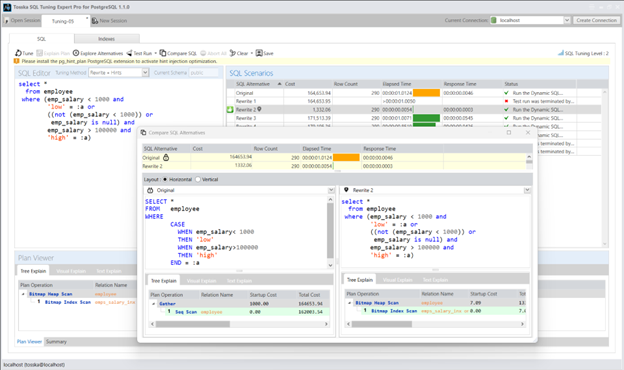
以下是我近期博客中的一条 SQL 语句。有读者询问在子查询的选择列表添加 +0(例如 b.emp_grade+0)对性能的影响。我很欣喜地得知,这个 +0 解决方案大约在 20 年前首次由我提出,用于解决特定子查询问题。不过该方法现已被 COALESCE(b.emp_grade, b.emp_grade) 替代——此举既能规避数据类型检测,又可预防意外错误。
今天,我想进一步探讨利用 IN 子查询优化 SQL 的其他解决方案。
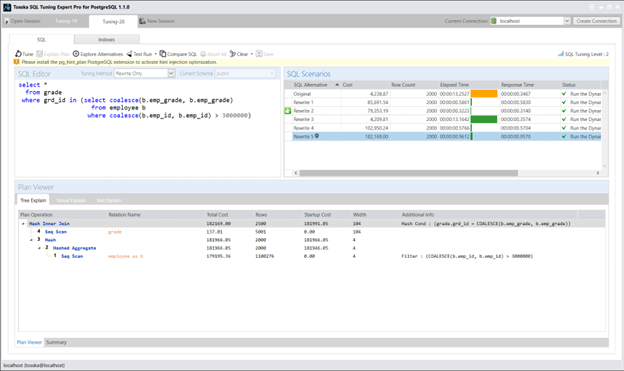
select *
from grade
where grd_id in (select b.emp_grade
from employee b
where b.emp_id > 3000000)

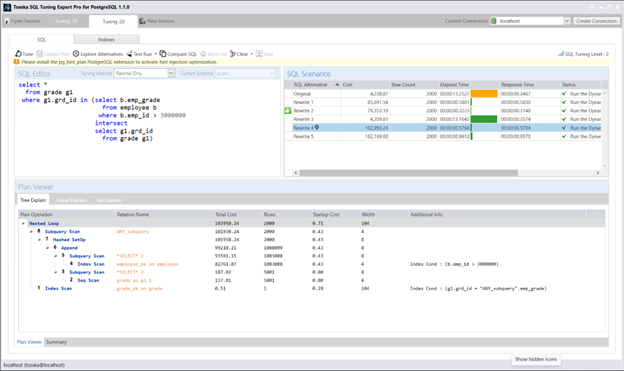
以下截图展示了由 Tosska SQL Tuning Expert Pro 通过’仅重写’选项和 ‘SQL调优智能=2’ 生成的替代SQL方案。我将分享更多SQL重写方法,全面展示各种可能方案,期待以SQL调优技术的精妙艺术激发读者的探索热情。
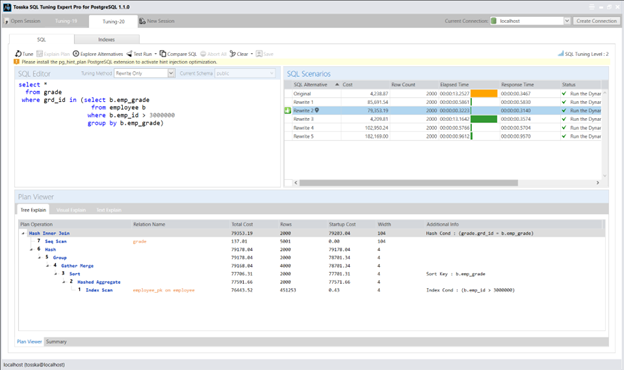
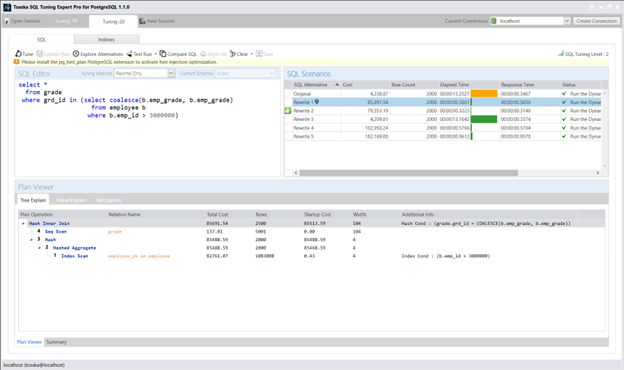
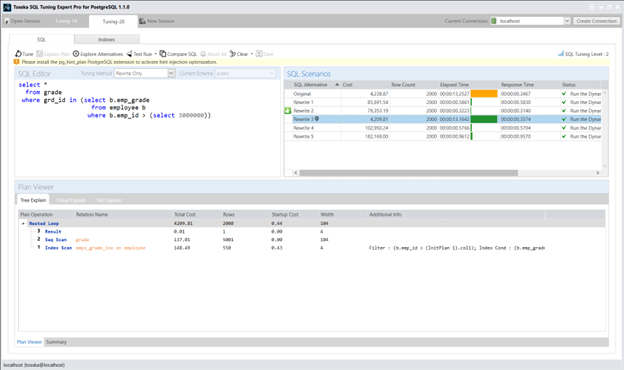
以下虽不深入探讨具体SQL重写语句细节,但我很乐意分享其余查询重写方案及其对应的执行计划:
Tosska SQL Tuning Expert Pro for PostgreSQL – Tosska Technologies Limited