利用SQL Server中的计划指南(Plan Guides)可以优化存储过程和触发器等数据库对象中特定查询的性能,从而提高查询效率,而无需修改应用程序的源代码。
以下是在不更改源代码的情况下,使用计划指南来优化SQL Server中第三方应用程序的SQL的步骤:
- 鉴定导致数据库对象性能问题的SQL语句。
- 创建一个计划指南,通过引入查询提示(query hints)来为指定的查询提供优化的执行计划,以影响优化器的决策过程。
- 测试计划指南,确保其提供了期望的性能改进,并且不会引起任何意外的副作用。
- 将计划指南部署到生产环境,并监控应用程序的性能,以确保计划指南正在使用,并提供了期望的性能改进。
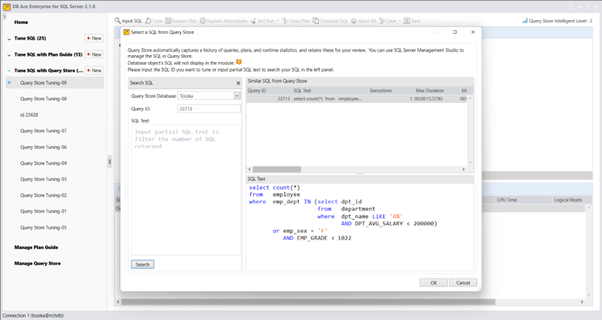
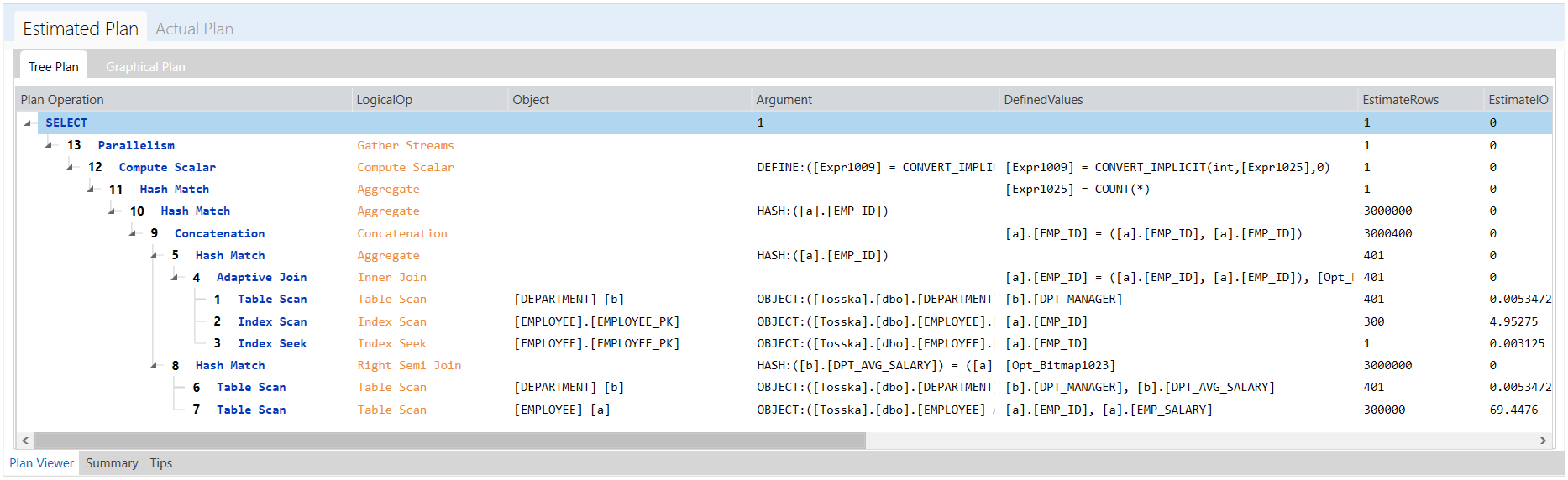
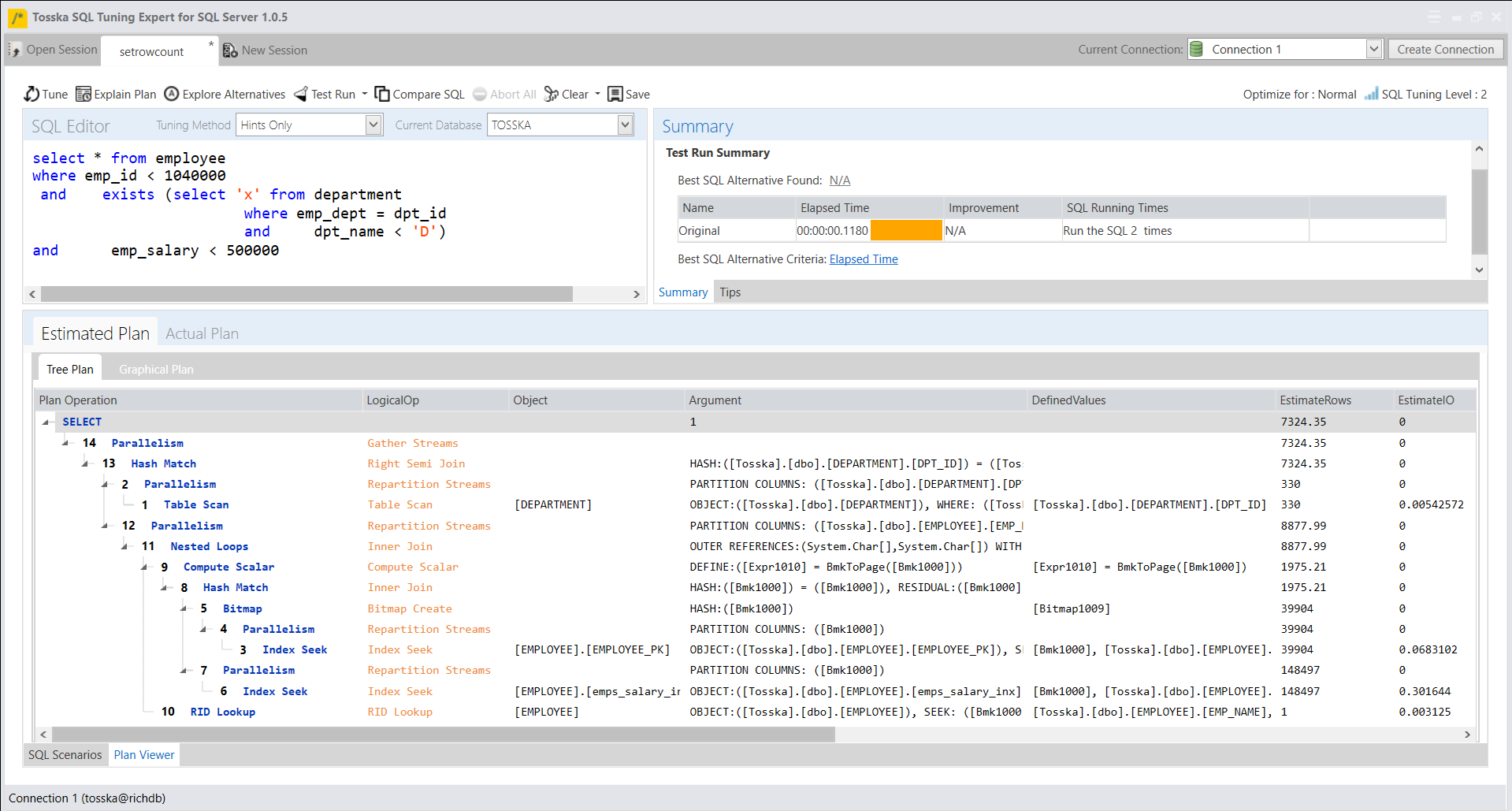
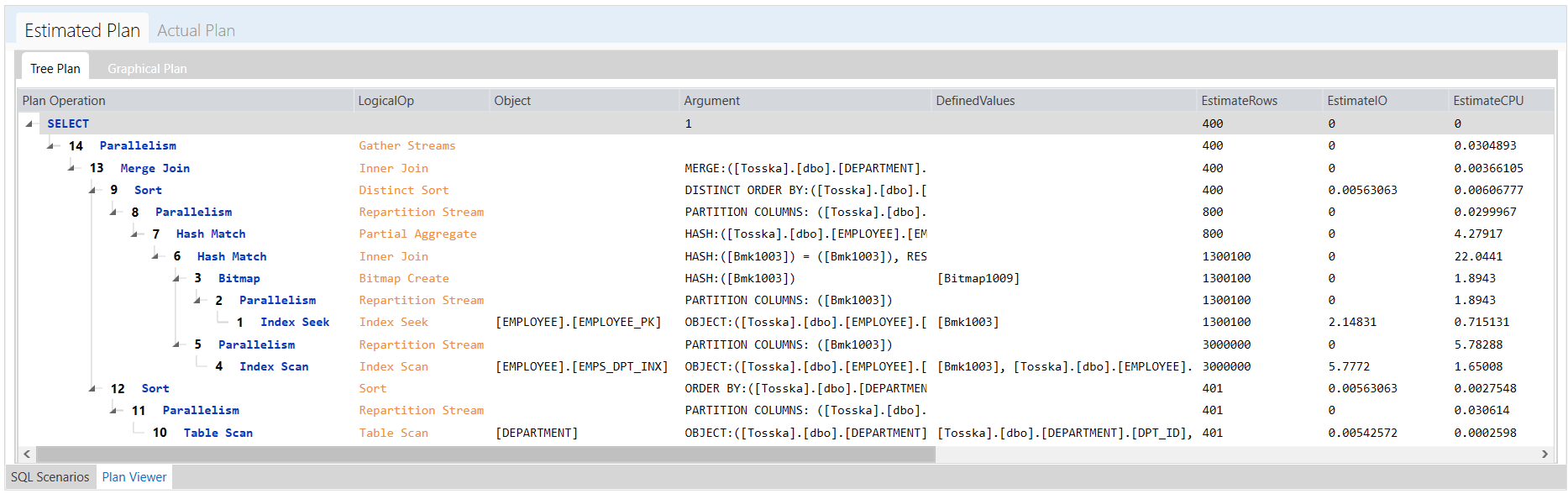
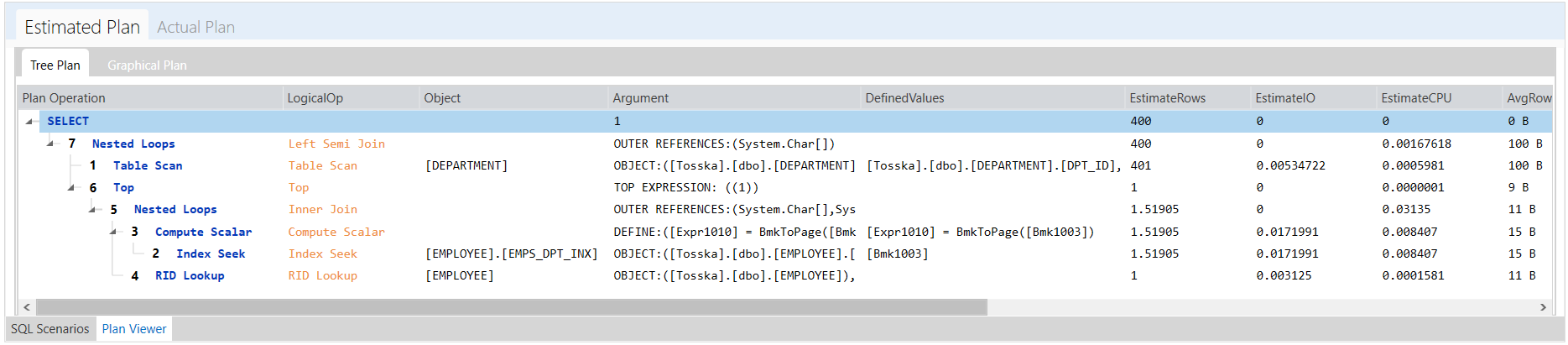
在优化执行中不修改源代码的应用程序中的数据库对象的SQL语句之前,关键是要了解SQL语句与计划指南中指定的语句的匹配情况,包括空格和注释。此外,还要确保匹配执行SQL语句的数据库对象。
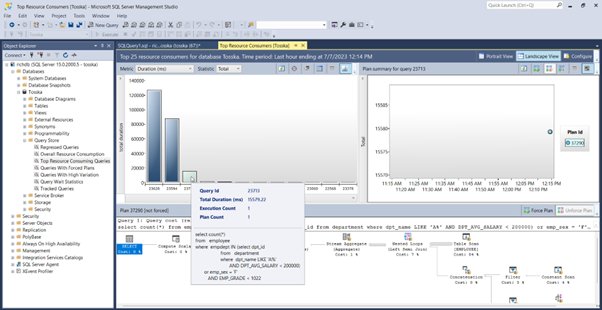
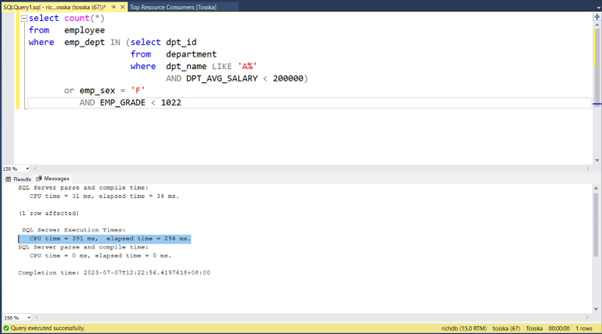
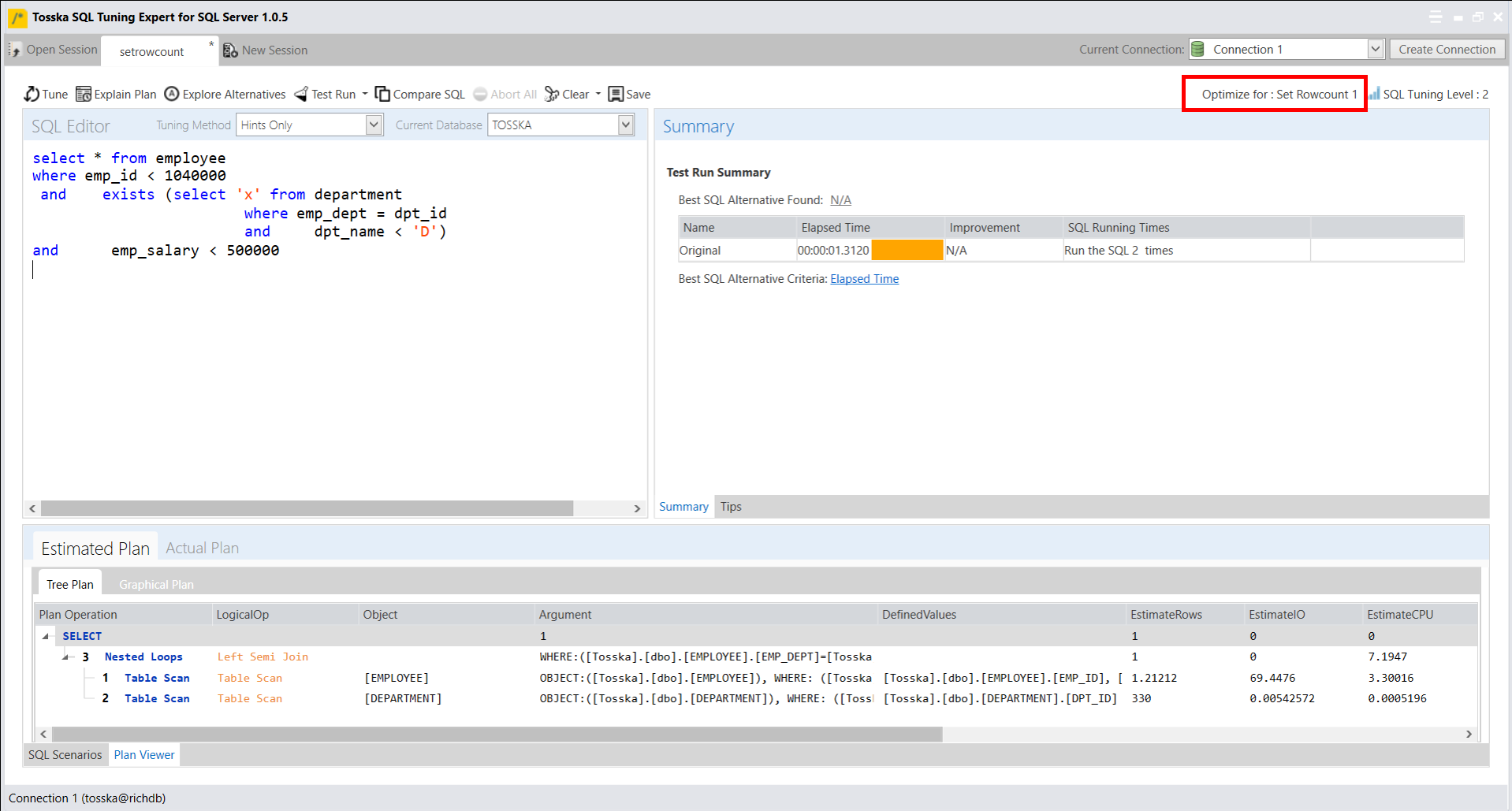
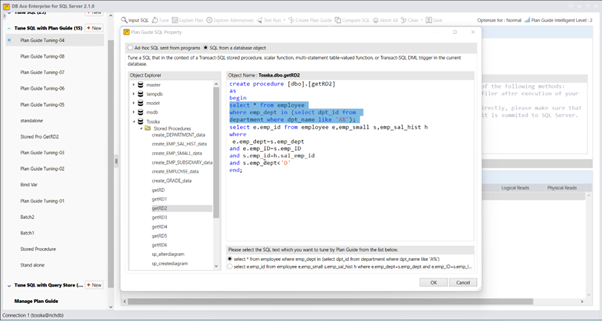
以下是一个示例,演示如何优化名为getRD2的数据库对象中的SQL语句。用户选择并突出显示了SQL语句。
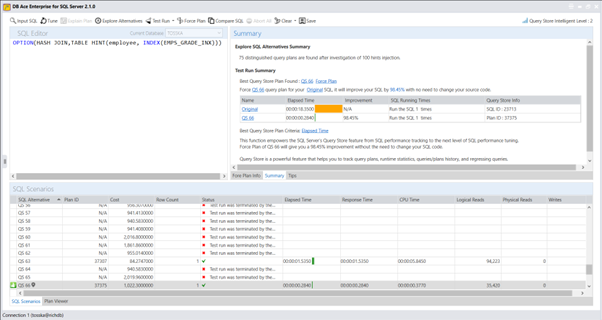
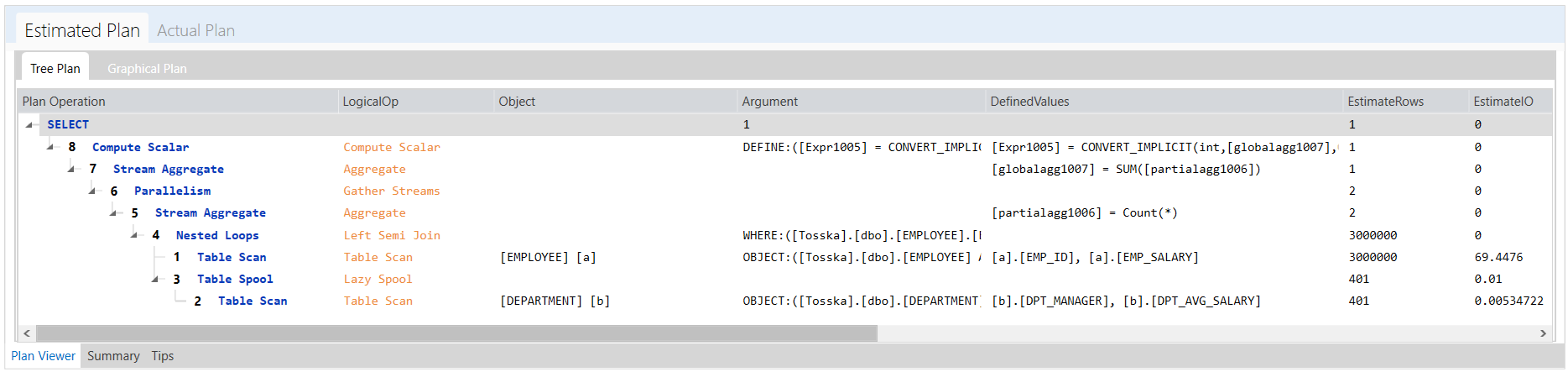
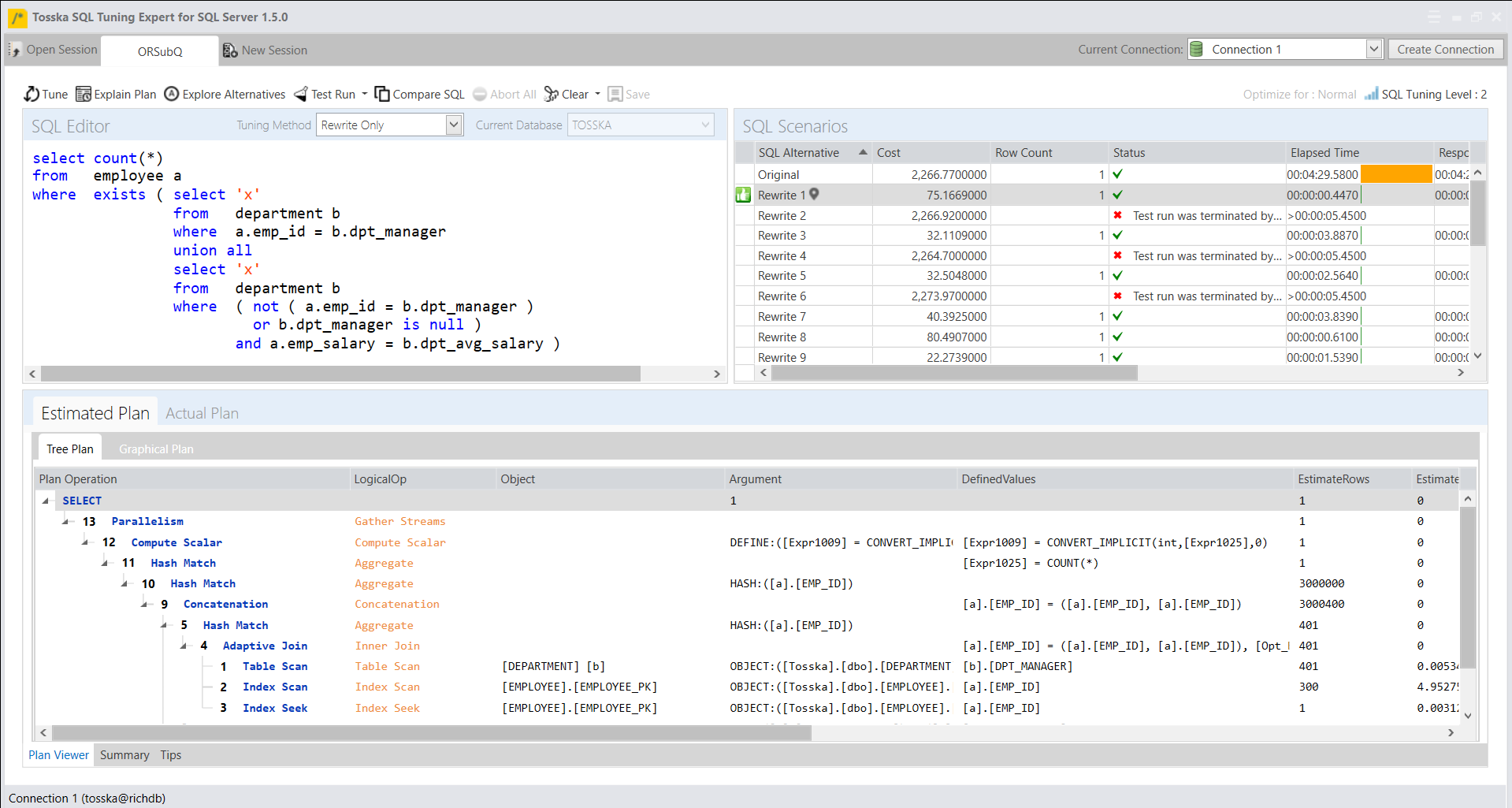
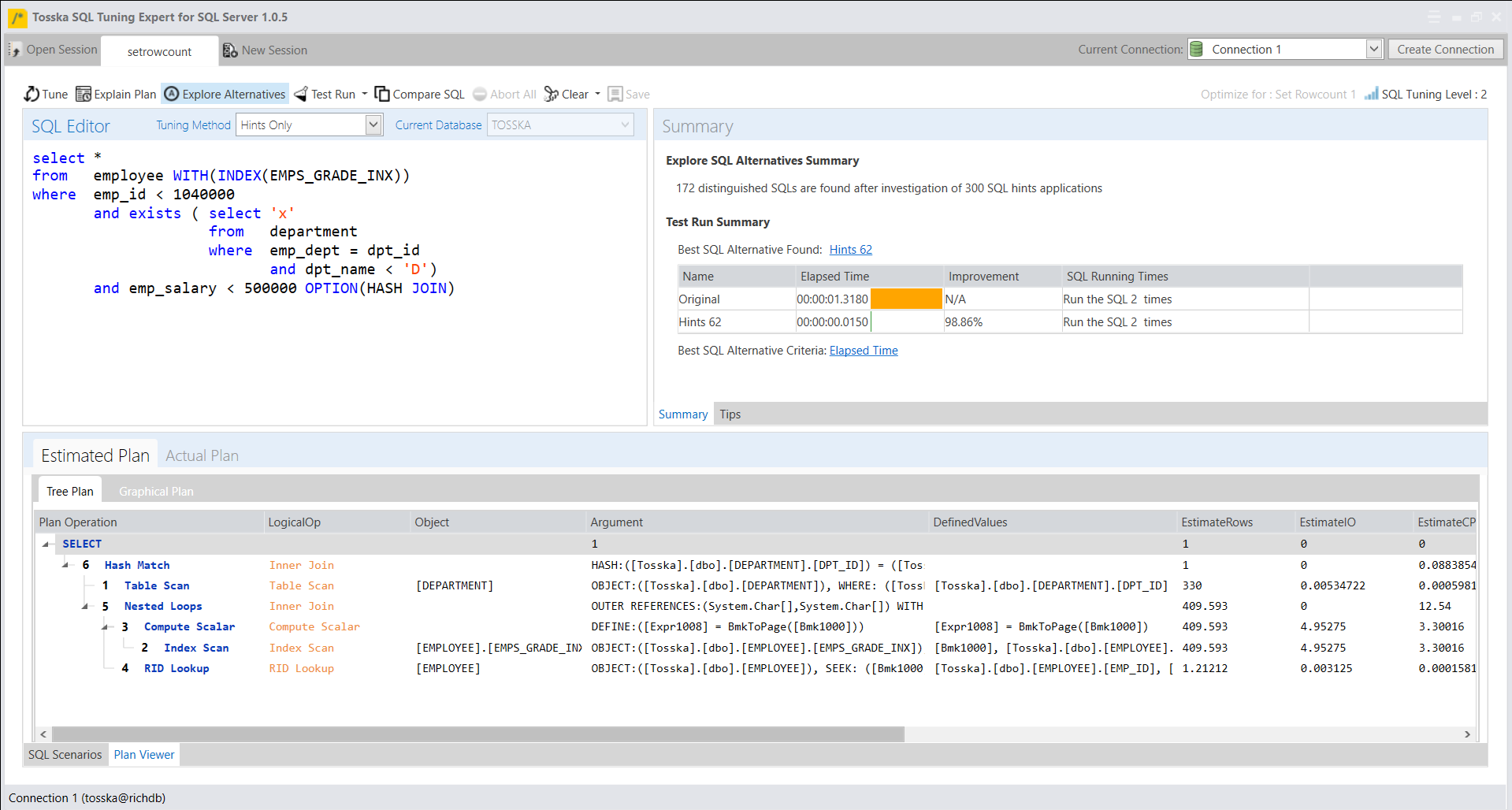
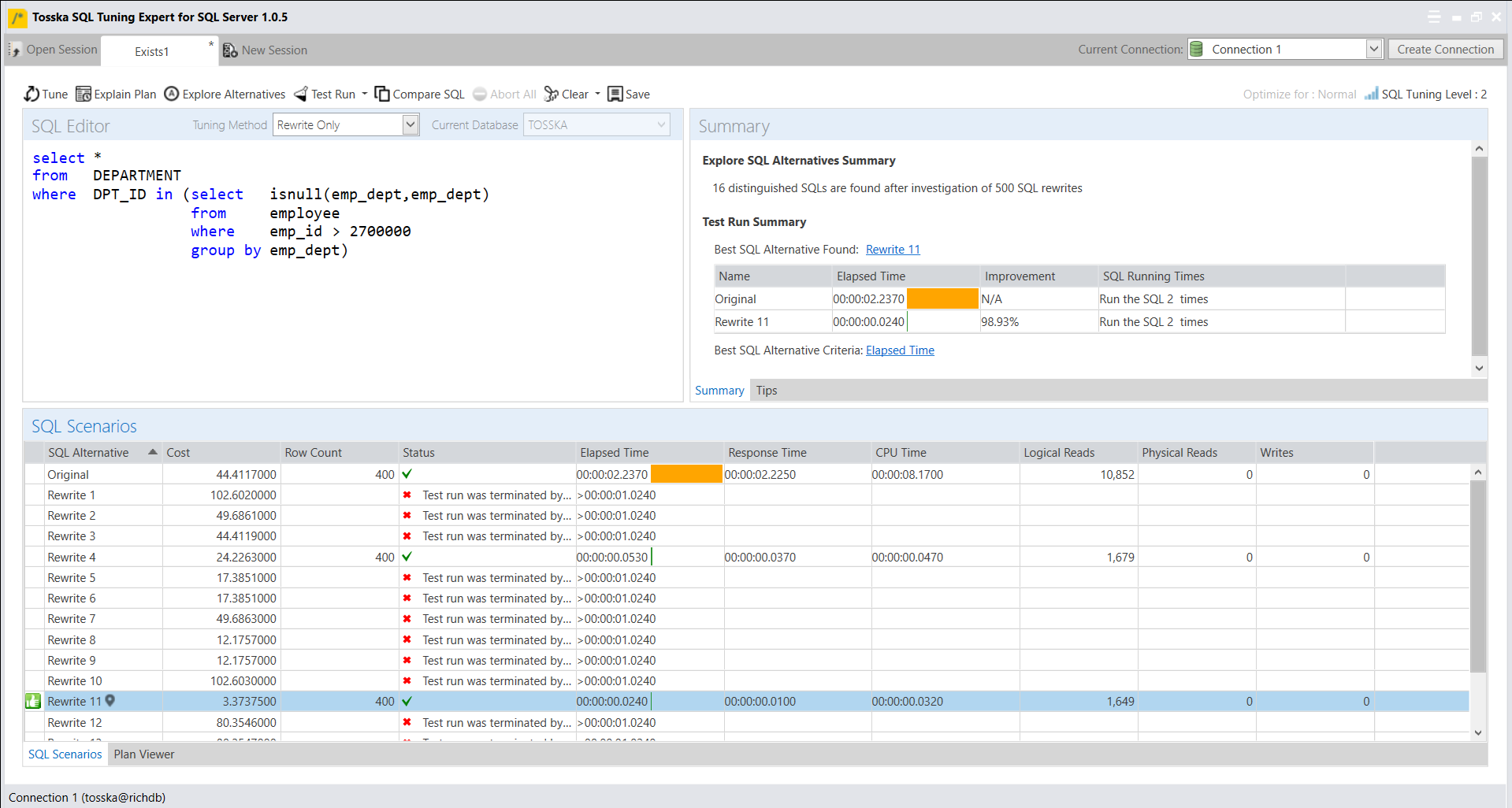
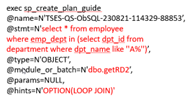
创建计划指南可能一开始看起来很复杂,但它是一种宝贵的方法,可以提高SQL性能,而无需修改源代码或缺乏必要的权限。最耗时的部分是使用sp_create_plan_guide系统存储过程中的@hints = N’OPTION(query_hint [ ,…n ])’参数来找到SQL语句的最佳查询提示。如果您对SQL调优技术了解不深或没有足够的时间进行试验,可以使用一种简化该过程的解决方案。它可以捕获SQL语句,识别SQL源类型,自动优化查询提示,并便于计划指南的轻松部署。
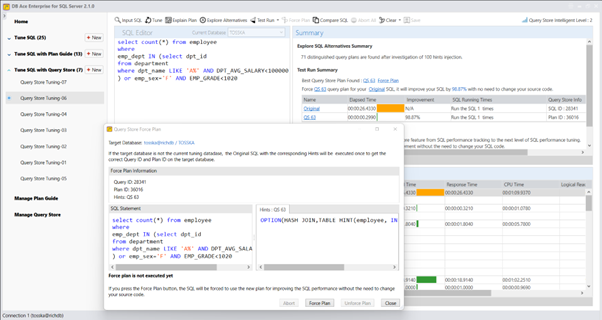
以下产品自动识别了一个计划指南,如附带的截图所示,可以将SQL性能提升75.81%。
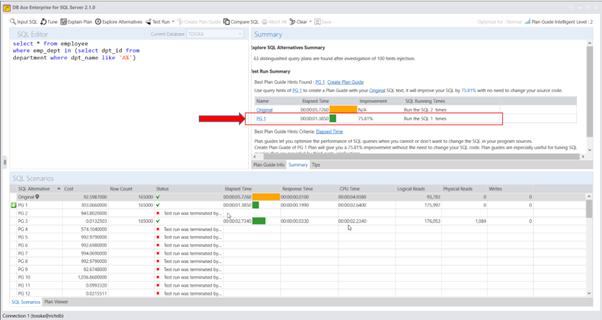
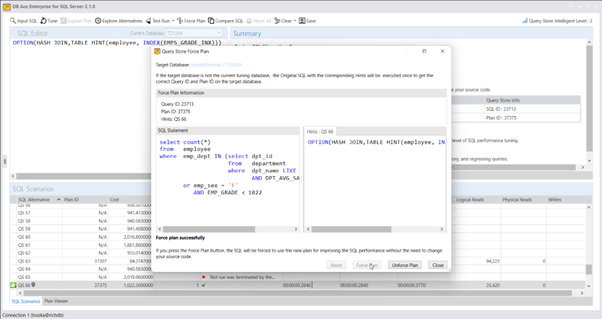
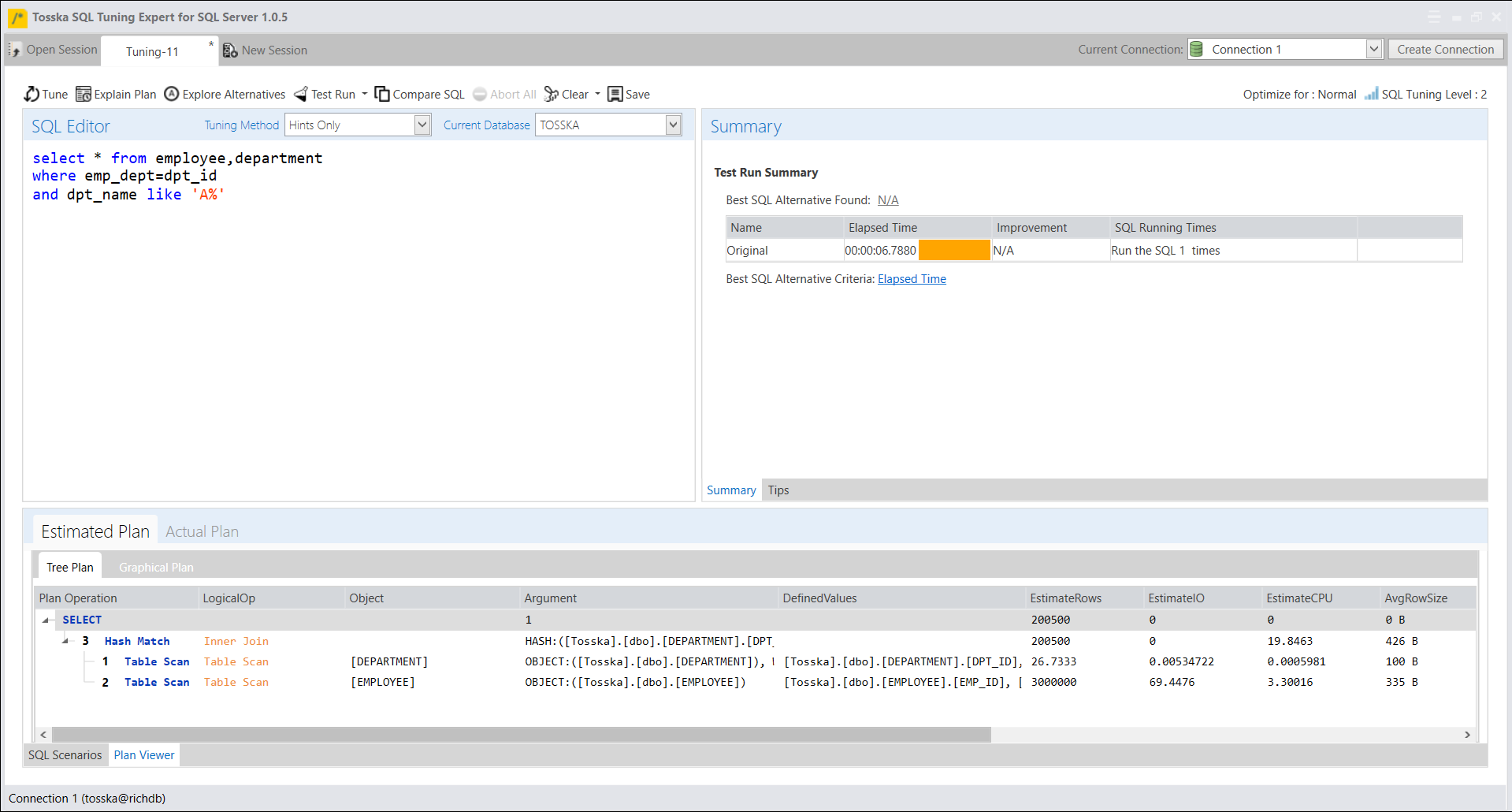
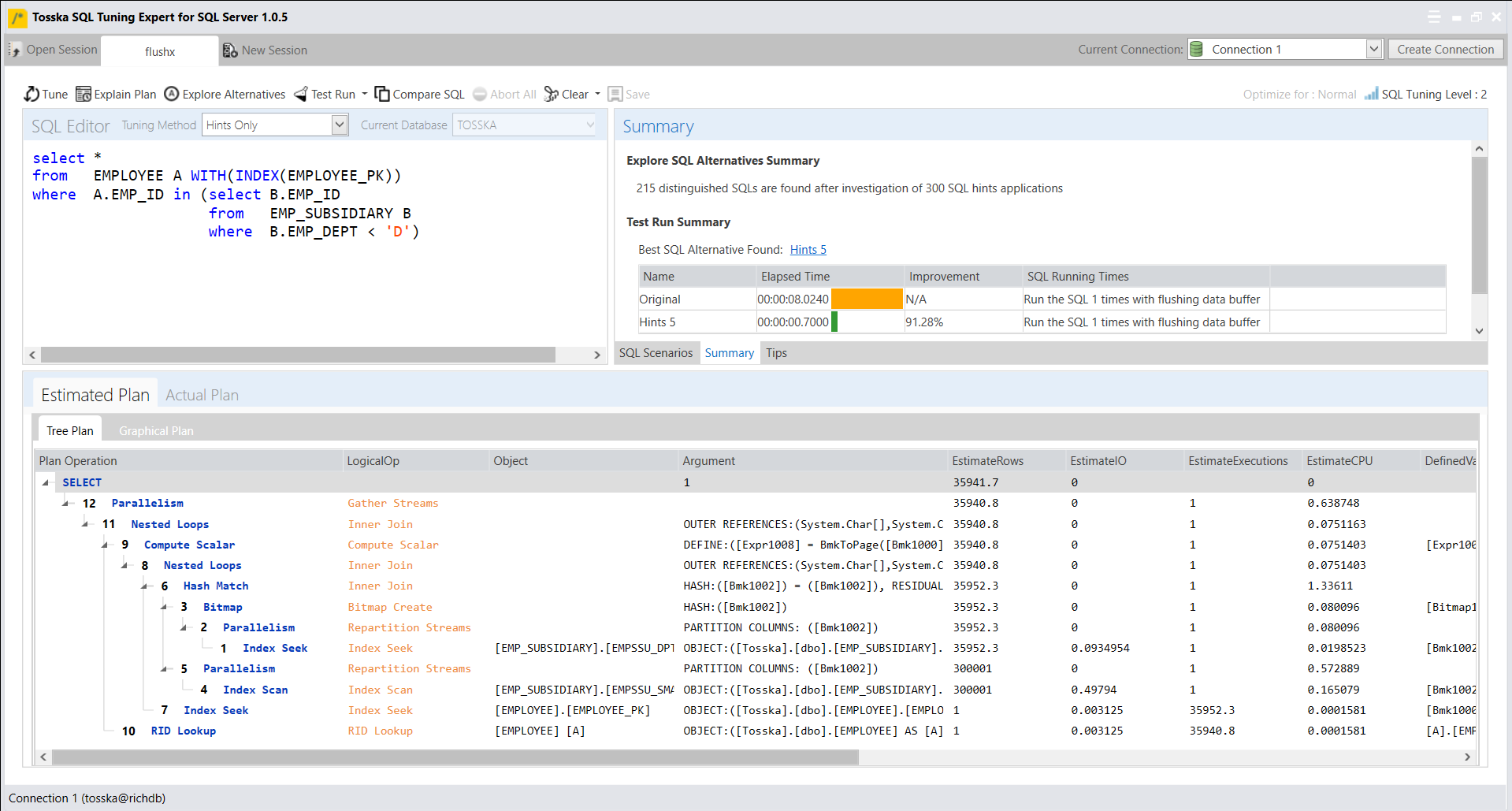
在确定了最佳的计划指南之后,我们可以将其与存储过程一起部署到SQL Server数据库中。这个部署将会改善名为getRD2的存储过程的性能,而无需对存储过程的源代码进行任何修改。
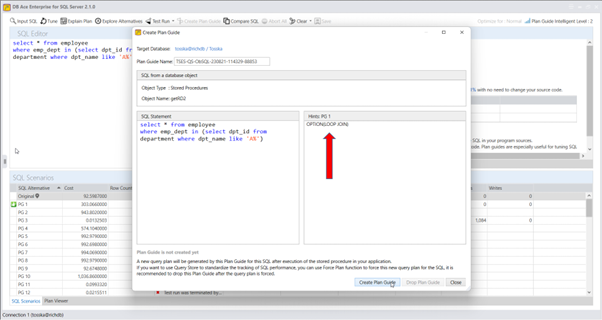
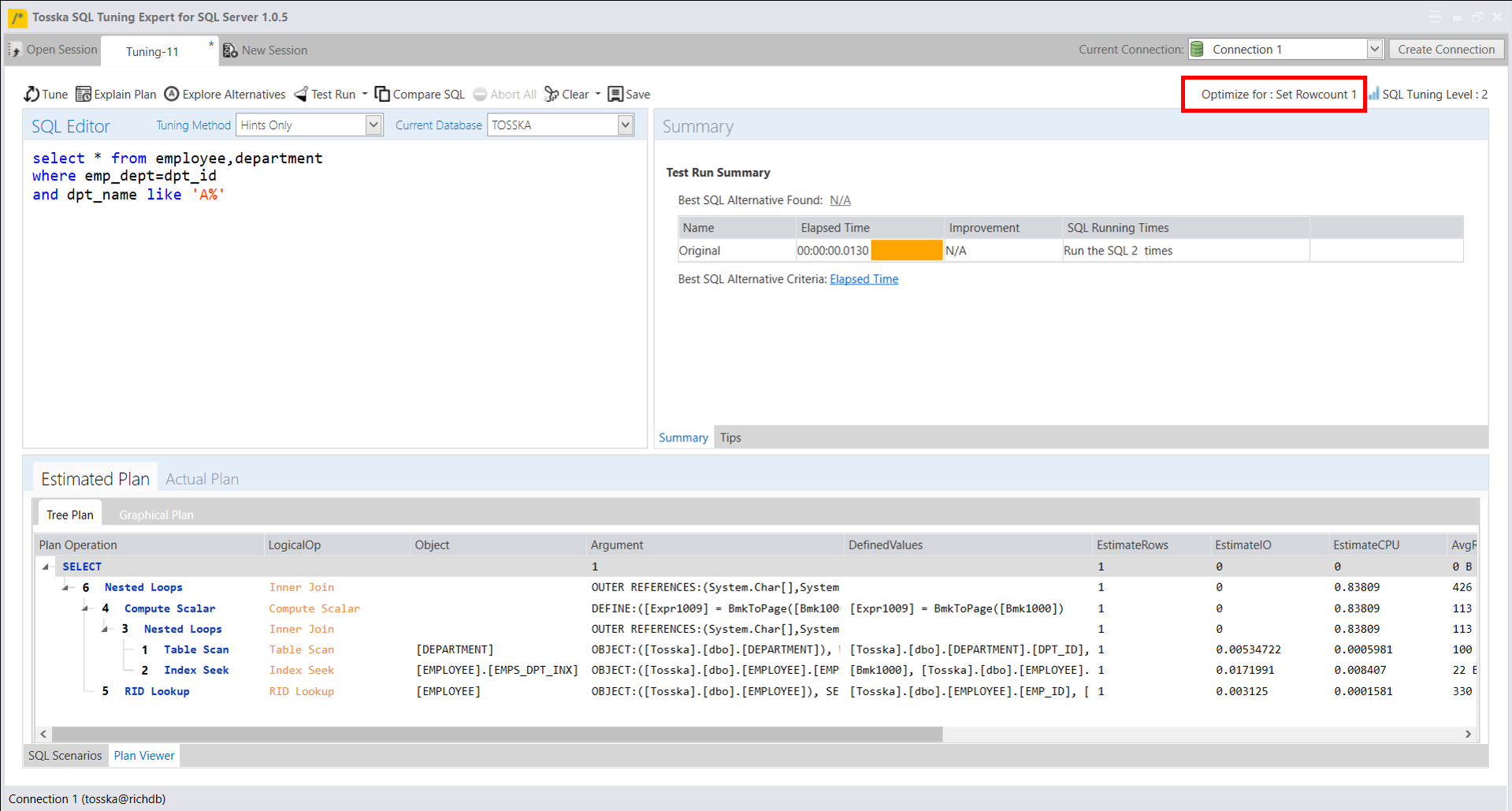
一旦您获得了适合SQL语句的合适提示解决方案,您还可以选择使用系统存储过程sp_create_plan_guide手动创建计划指南。
如需详细信息,请访问我们的网站并观看我们的演示视频。
Tosska DB Ace Enterprise for SQL Server – Tosska Technologies Limited
DBAS Tune SQL PG Object – YouTube