在我的最新博客文章中,我将探讨针对使用 “NOT IN” 子查询的 SQL 语句的额外优化方案。
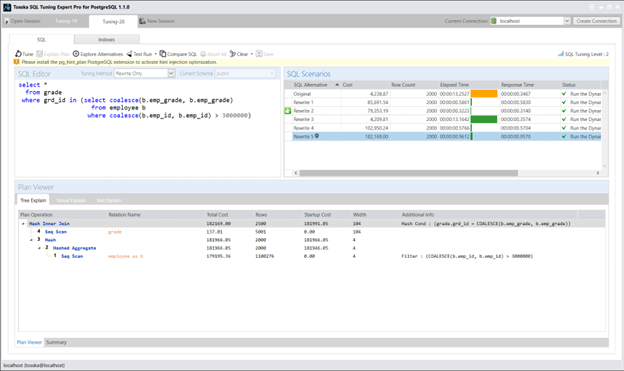
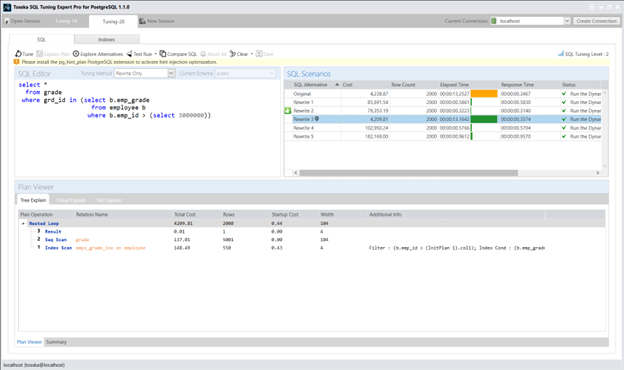
以下是一个带有 NOT IN 子查询的 SQL 示例。该语句从成绩表(grade)中查询记录,要求当员工表(employee)中 emp_id 大于 3000 时,grd_id 不匹配任何 emp_grade 值:
select *
from grade
where grd_id not in (select b.emp_grade
from employee b
where b.emp_id > 3000)
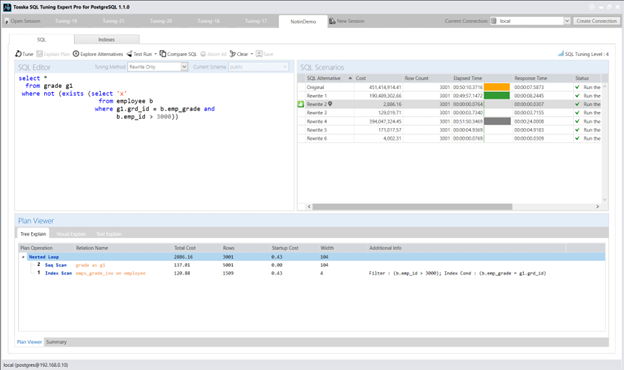
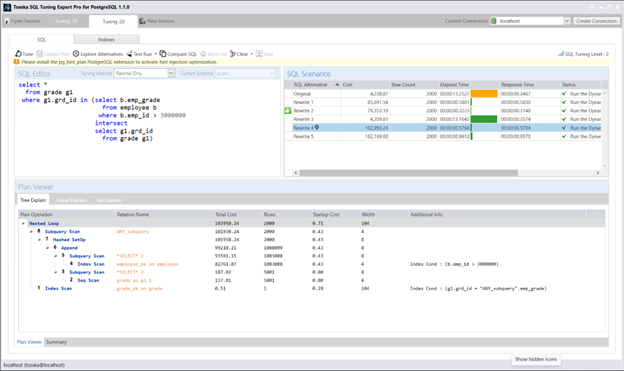
在我上一篇文章中,通过将原始查询改写为使用NOT EXISTS语句,在我的数据库环境中实现了最佳性能表现。然而需要注意的是,这种方法并非对所有数据库结构设计都普遍适用:
select *
from grade g1
where not (exists (select ‘x’
from employee b
where g1.grd_id = b.emp_grade and
b.emp_id > 3000))
现在我将列出其他高性能解决方案:
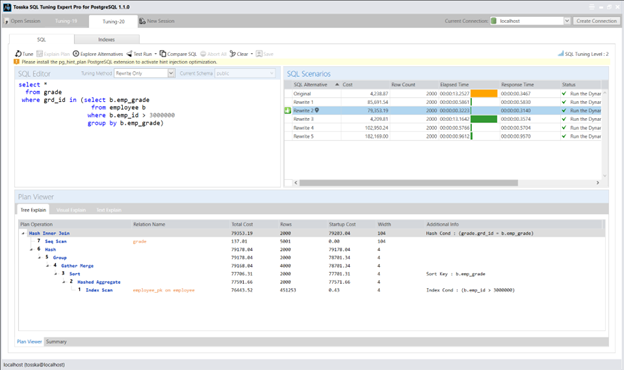
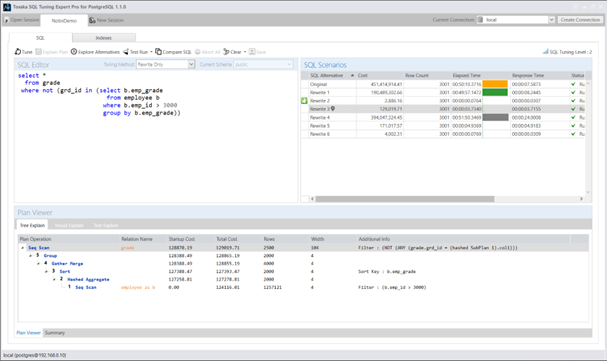
方案1——添加GROUP BY子句
通过添加GROUP BY子句,可促使优化器预先对员工表进行排序和哈希聚合处理:
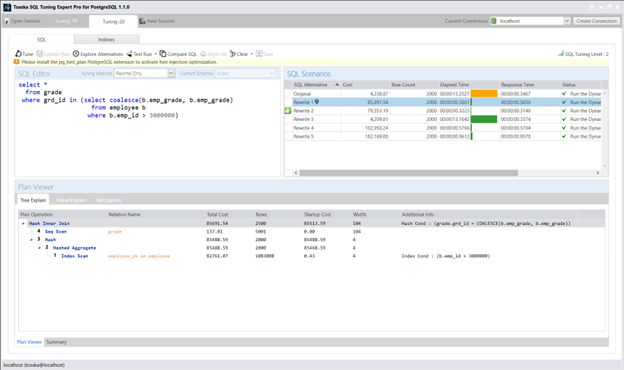
方案2——添加COALESCE函数
通过添加COALESCE(b.emp_grade, b.emp_grade),会阻止员工表(employee)使用潜在索引,导致该表被迫进行顺序扫描(Seq Scan),从而改变原查询执行路径中的连接顺序:
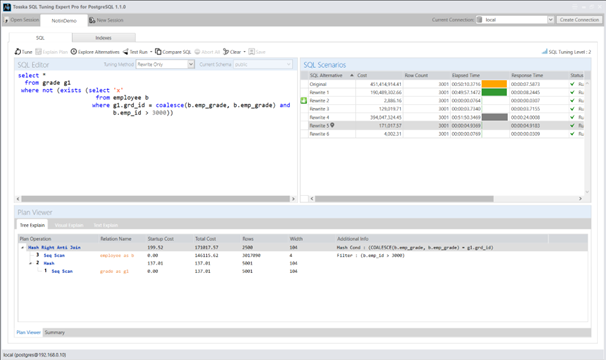
方案3——替换字面值为子查询
通过将字面值3000替换为子查询(SELECT (3000)),会隐藏常量特性,从而阻止优化器在b.emp_id字段上使用索引:
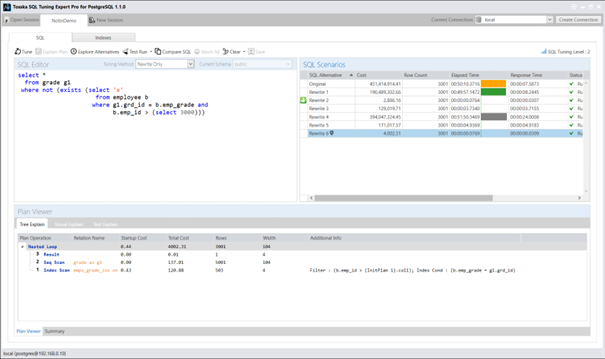
Tosska SQL Tuning Expert Pro for PostgreSQL – Tosska Technologies Limited