对于不经常执行的SQL语句,相关的数据可能不在缓存区,冷缓存会显著的影响这类SQL语句的性能。 用于热缓存的高性能SQL语句在冷缓存环境中可能表现的不好。经验丰富的开发人员会调优他们的SQL, 使其在两种情况下都能得到良好运行。
下面是一个SQL示例:
select * from
EMPLOYEE A
where A.EMP_ID IN (SELECT B.EMP_ID from EMP_SUBSIDIARY B
where B.EMP_DEPT < ‘D’)
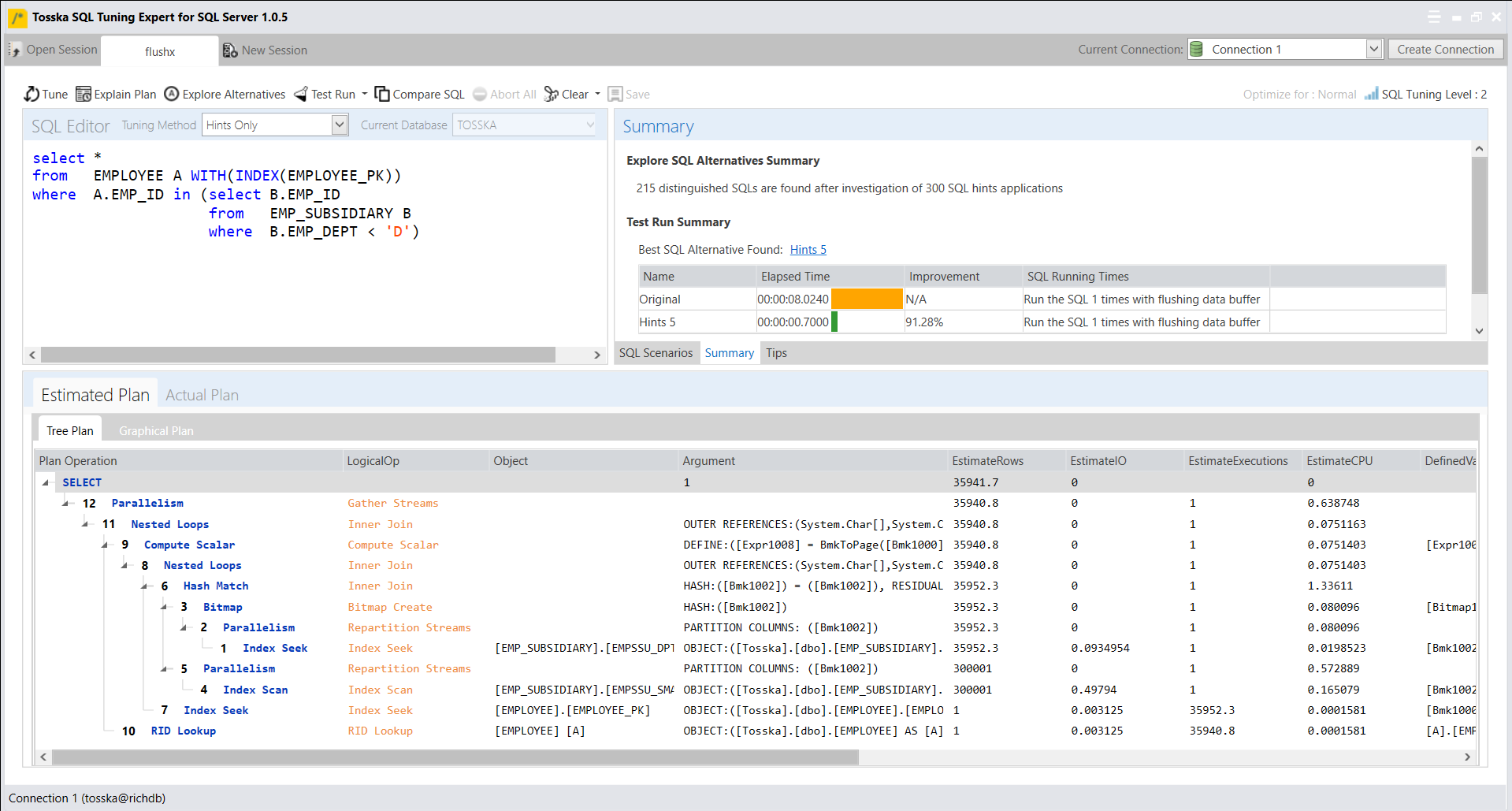
下面是Tosska的树结构执行计划,第一次执行因为缓存延迟需要8.024秒,第二次执行无需缓存延迟只需要3.7秒。

根据执行计划,您可能发现IO消耗最多的是[EMPLOYEE]表的表扫描。为了模拟冷缓存环境,我们可以在每次执行SQL语句前使用DBCC DROPCLEANBUFFERS命令来清除数据缓存。
让我为这条SQL添加OPTION(LOOP JOIN)提示,并尝试将执行计划的哈希匹配更改为嵌套循环连接。因此,将使用[EMPLOYEE]的EMP_ID(EMPLOYEE_PK)和RID查找,而不是使用表扫描。我希望RID查找可以从硬盘中选择较少的数据,同时在[EMPLOYEE]和[EMP_SUBSIDIARY]中匹配EMP_ID。
select *
from EMPLOYEE A
where A.EMP_ID in (select B.EMP_ID
from EMP_SUBSIDIARY B
where B.EMP_DEPT < ‘D’) OPTION(LOOP JOIN)
根据下面的执行计划,携带数据缓存开销的执行时间从8.024秒减少到1.565秒,物理读也从190,621减少到39,044。如果您用SQL Server的EstimateIO乘以EstimiateExecutions来得到IO估计值,这是错误的。

下面的人工智能调优工具还提供了其它更好的调优解决方案:
Tosska SQL Tuning Expert (TSES™) for SQL Server® – Tosska Technologies Limited
下面带有提示的SQL语句生成一个更复杂的执行计划,最好的执行时间为0.7秒。该SQL是在冷缓存下进行调优的,每次执行SQL语句之前都会清除缓存数据。